Spark’s caching mechanism can be leveraged to optimize performance. Here are some facts and caveats about caching.
Basics
Ways to cache
Dataframes or tables may be cached in the following ways.
df.cache()- lazy,dfis only evaluated after an action is called.spark.catalog.cacheTable('t0')- also lazy.spark.sql('cache table t0')- eager,t0is evaluated immediately.- In Spark 3,
spark.sql("CACHE LAZY TABLE t0")allows cachingt0lazily via the Spark SQL engine.
Ways to “uncache”
df.unpersist()- convenient when there is a variable readily referencing the dataframe.spark.catalog.clearCache()- will clear all dataframes/tables cached via any of the above 3 ways.spark.sql("UNCACHE TABLE t0")- uncache tables cached viaspark.sql().
>>> l = [('Alice', 1)]
>>> df = spark.createDataFrame(l) # create sample temp tables
>>> df
DataFrame[_1: string, _2: bigint]
>>> df1 = spark.createDataFrame(l)
>>> df2 = spark.createDataFrame(l)
>>> df.cache() # cache df lazily
DataFrame[_1: string, _2: bigint]
>>> df1.registerTempTable('df1')
>>> spark.catalog.cacheTable('df1') # cache df1 lazily
>>> df2.registerTempTable('df2')
>>> spark.sql('cache table df2') # cache df2 eagerly
DataFrame[]
>>> for (id, rdd) in spark.sparkContext._jsc.getPersistentRDDs().items(): print id # all 3 dfs are cached
...
28
18
16
>>> spark.catalog.clearCache()
>>> for (id, rdd) in spark.sparkContext._jsc.getPersistentRDDs().items(): print id # all cached dfs are cleared
...
>>>
Caveats
Temporary tables in Spark SQL are not automatically cached
Information online (e.g., here and here) says that temporary tables created in SQL are computed only once and can be reused. But the physical plans of SparkSQL shows that the temp tables are evaluated each time they are used. Consider the following query:
query = '''
WITH t0 AS (
SELECT
*
FROM
selected_companies
WHERE
region = 'TH'
),
t1 AS (
SELECT
*
FROM
t0
WHERE
business = 1000
),
t2 AS (
SELECT
*
FROM
t0
WHERE
business = 2000
)
SELECT
*
FROM
(SELECT * FROM t1)
UNION
(SELECT * FROM t2)
'''
print query
df = spark.sql(query)
df.show() # triggers evaluation
Execution plan of this query shows that t0 is effectively evaluated twice.
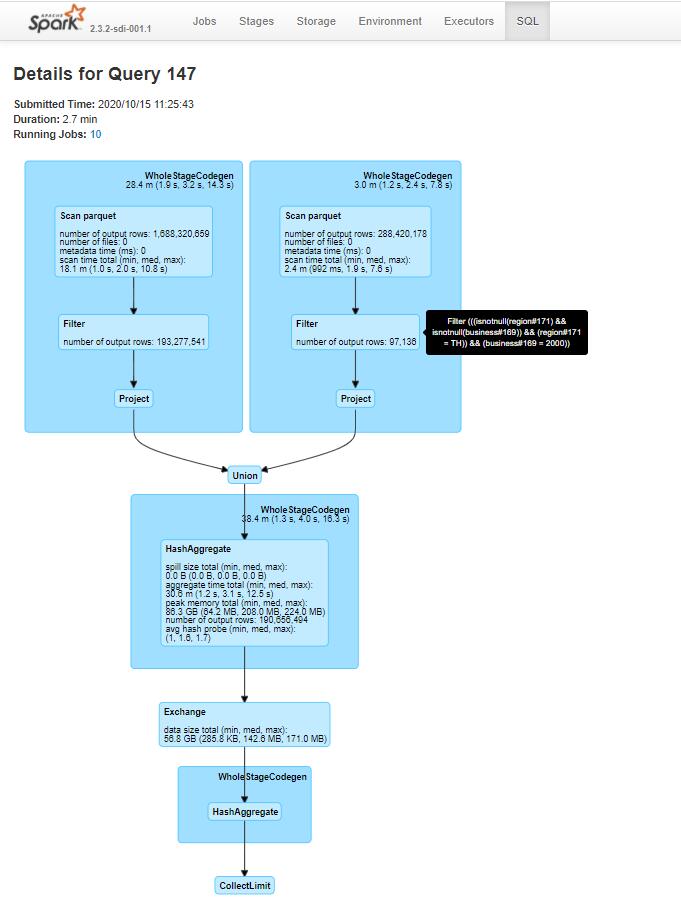
If t0 is explicitly cached, e.g.,:
query = '''
SELECT
*
FROM
selected_companies
WHERE
region = 'TH'
'''
print query
t0 = spark.sql(query)
t0.cache() # lazy
t0.registerTempTable('t0')
# spark.catalog.cacheTable('t0') # lazy, same effect as t0.cache() in terms of physical plan
# spark.sql("cache table t0") # eager, t0 is evaluated immediately
query = '''
WITH t1 AS (
SELECT
*
FROM
t0
WHERE
business = 1000
),
t2 AS (
SELECT
*
FROM
t0
WHERE
business = 2000
)
SELECT
*
FROM
(SELECT * FROM t1)
UNION
(SELECT * FROM t2)
'''
print query
df = spark.sql(query)
df.show()
Execution plan of the second query shows that t0 is stored in cache memory and reused by t1 and t2.
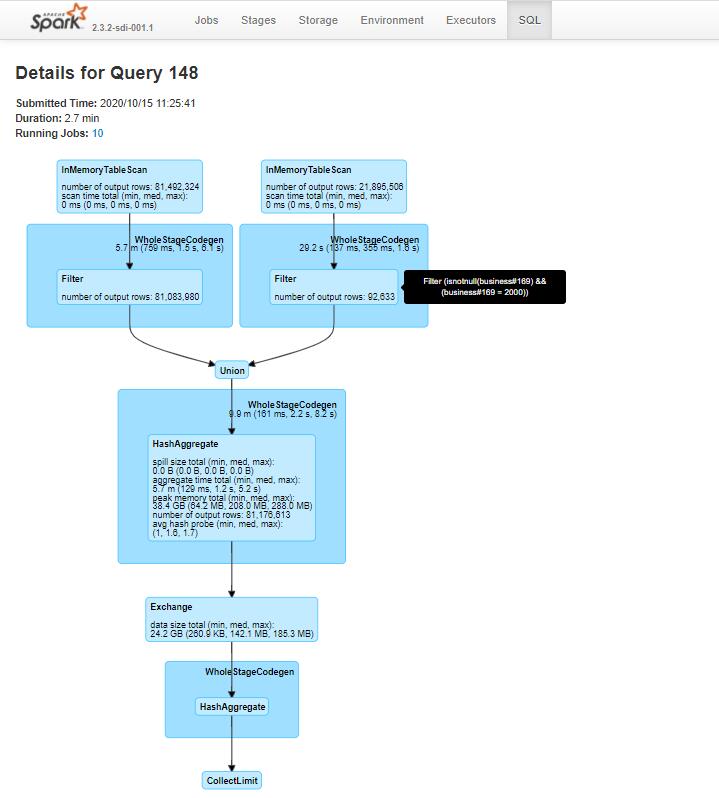
To cache or not to cache
If the time it takes to compute a table * the times it is used > the time it takes to compute and cache the table, then caching may save time. Otherwise, not caching would be faster.
In other words, if the query is simple but the dataframe is huge, it may be faster to not cache and just re-evaluate the dataframe as needed. If the query is complex and the resulting dataframe is small, then caching may improve performance if the dataframe needs to be reused.
In the above example, the query is simple but the underlying dataframe is quite huge. As a result, caching t0 takes more time (~14min) than not caching (~9min).


Caching eagerly improves readability in YARN UI
For Spark jobs that use complex SQL queries, the SQL page in YARN UI is a good way to track the progress of each query. However due to Spark’s lazy evaluation, if the intermeidate tables are not cached eagerly or don’t have any actions called upon them (e.g., df.show()), all the queries will be lumped together into one huge execution plan to be evaluated at the last step, e.g.:
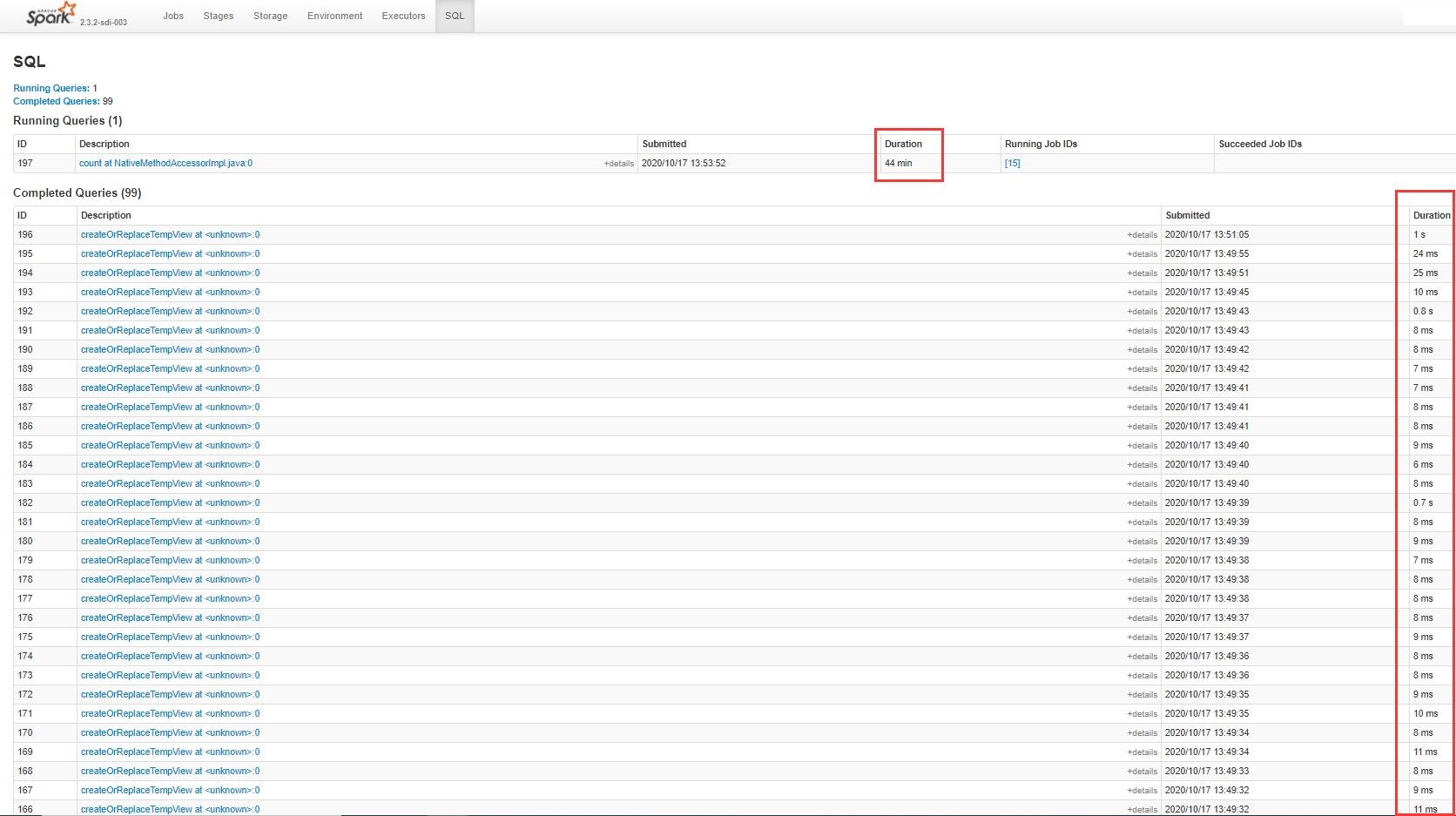
So if a dataframe needs to be cached at all, can consider caching eagerly using spark.sql('cache table xxx'), so that the query execution can be broken down into more trackable pieces. Moreover, when optimizing queries, it is recommended to cache each intermediate table eagerly, so as to make identifying bottlenecks easier.
Caching prevents stackoverflow in nested query plans
If the query plan structure is nested too deeply, Spark may throw StackOverflowError (see [here] (https://stackoverflow.com/questions/25147565/serializing-java-object-without-stackoverflowerror) and here). This occurs when there are too many nested layers of column computation in intermediate tables, .e.g.,
WTIH t1 AS (
SELECT
*,
complex_function1(c0) AS c1
FROM t0
),
t2 AS (
SELECT
*,
complex_function2(c1) AS c2
FROM t1
),
t3 AS (
SELECT
*,
complex_function2(c1) AS c3
FROM t2
)
...
Alternatively, in pyspark:
df = df.withColumn('c1', complex_udf1(df['c0']))
df = df.withColumn('c2', complex_udf2(df['c1']))
df = df.withColumn('c3', complex_udf2(df['c2']))
...
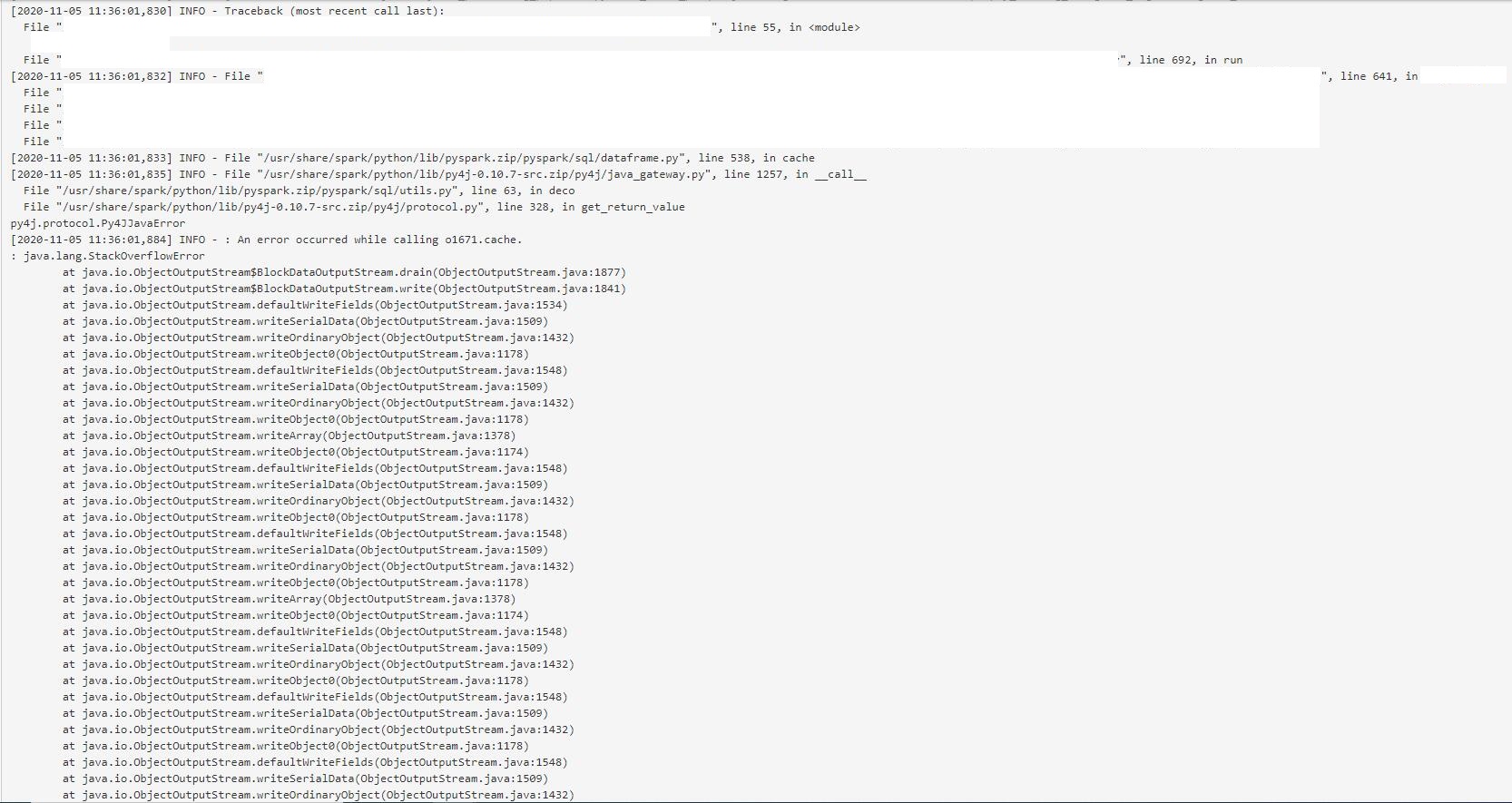
One possible solution is to add df.cache() somewhere in the middle of the series of transformations. It seems that doing so would store the query plan so far somewhere off-stack, thereby reducing the stack and preventing stackoverflow.
Among the series of transformations, there is a range where adding df.cache() is effective. E.g., in the example below, adding df.cache() too early may cause the transformations behind to overflow, and adding df.cache() too late may cause the transformations in front to overflow.
df = df.withColumn('c1', complex_udf1(df['c0']))
df = df.withColumn('c2', complex_udf2(df['c1']))
# df.cache() effective range lower limit
df = df.withColumn('c3', complex_udf3(df['c2']))
df = df.withColumn('c4', complex_udf4(df['c3']))
df = df.withColumn('c5', complex_udf5(df['c4']))
df.cache() # effective
df = df.withColumn('c6', complex_udf6(df['c5']))
df = df.withColumn('c7', complex_udf7(df['c6']))
df = df.withColumn('c8', complex_udf8(df['c7']))
df = df.withColumn('c9', complex_udf9(df['c8']))
# df.cache() effective range upper limit
df = df.withColumn('c10', complex_udf10(df['c9']))