- Approaches
Spark has 2 deploy modes, client mode and cluster mode. Cluster mode is ideal for batch ETL jobs submitted via the same “driver server” because the driver programs are run on the cluster instead of the driver server, thereby preventing the driver server from becoming the resource bottleneck. But in cluster mode, the driver server is only responsible for running a client process that submits the application, after which the driver program would be run on a different machine in the cluster. This poses the following challenges:
- We can’t access the driver program’s log from the driver server (only the client process’ log is available to the driver server).
- We can’t terminate the spark application via Ctrl-C or by marking success/killing tasks in the Airflow scheduler (doing so will only kill the client process running on the driver server, not the spark application itself).

We want to make use of cluster mode’s advantage and find workarounds to:
- Access and store logs for recent as well as historical jobs conveniently;
- View log conveniently in real time;
- Kill applications via keyboard or Airflow.
Approaches
Redirect log to console in real time
A naiive approach is to attempt to to mimic the conveniences of client mode. Our search did not turn up any method that can redirect aggregated logs to our chosen directory in real time or print it to console.
- This post does not say can.
- This post seems to want to do the same thing as we do, but no solutions are raised.
- This post says cannot.
Collect aggregated log after application is finished
Instead, a more practical approach is to:
- Collect the aggregated logs to a designated directory using the
yarn logs -applicationId $applicationIdcommand after the spark application is finished. E.g., to collect log in HDFS:yarn logs -applicationId $applicationId -log_files stdout -am 1 | hadoop fs -appendToFile - /user/xxx/log_--dates_2020-09-21.txtor in the driver server’s local file system:
yarn logs -applicationId $applicationId -log_files stdout -am 1 |& tee -a /home/xxx/log_--dates_2020-09-21.txt - View log in real-time using the
watchandtailcommands or YARN’s UI. - Use
yarn application -kill $applicationIdto kill the spark application upon receiving termination signals from keyboard or Airflow.
To implement this approach, we need to consider the following:
- ApplicationId: How to get the applicationId that we need to collect aggregate logs from YARN and relay termination signals to the driver program;
- Flow control: How to make sure that log collection is triggered only after the application is finished (either exiting normally or terminating upon error), so that the log is complete.
The applicationId is conveniently available via spark.sparkContext.applicationId in the .py script after creating a spark session, but the flow control is more conveniently done in shell script where we have a clear idea of when the spark-submit process terminates. We can put the log collection command in either the .py script or the shell script, with the understanding that either approach has trade-off.
In .py script: Use customized sys.excepthook to trigger log collection upon any exception (X)
In .py script, the applicationId can be easily accessed via spark.sparkContext.applicationId. But to put the log collection command in .py script, we need to make sure that any event that triggers program termination, be it normal termination or exception, is caught and redirected to log collection. E.g., we could wrap a try...except block around the main entry point of the driver script in the pipeline. Yet this does not capture errors in the definition of the pipeline itself, or our customized common modules that are imported by the driver script. Instead, we considered using a customized sys.excepthook to catch exceptions globally.
A customized excepthook is a function with 3 arguments type, value, tback and performs customized handling of the caught exception. In the example below, except_hook returns a customized excepthook which, upon catching any exception, collects log using the applicationId supplied and calls the default handler sys.__excepthook__() to handle the exception.
def collect_log(applicationId, logPath, logger):
cmd = 'yarn logs -applicationId {application_id} -am 1 |& tee -a $logPath'.format(
application_id=applicationId, logPath=logPath)
logger.info('Collecting log to ' + logPath)
logger.info(cmd)
subprocess.call(cmd, shell=True)
return True
def except_hook(applicationId, logPath, logger):
def handler(type, value, tback):
exc_info = sys.exc_info()
# Display the *original* exception
traceback.print_exception(*exc_info)
del exc_info
collect_log(applicationId, logPath, logger)
sys.__excepthook__(type, value, tback)
return handler
...
sys.excepthook = except_hook(applicationId, logPath, logger) # define customized excepthook
This approach, however, is flawed in that the definition of our customized excepthook requires a running spark session, which only exists in the config scripts of each data model, and not in the common modules. Other drawbacks include the need to carefully manage the order of imported modules, e.g., the customized excepthook should be defined before other objects in the driver script, or some errors may be missed and the log collection step wouldn’t be triggered.
In shell script: Parse client process’ output to get applicationId and trigger log collection after spark-submit is finished
Another approach we considered and ended up adopting is to trigger log collection in shell script after the spark-submit process is finished. This has the advantage of providing a clear indication when the spark-submit process terminates. The trade-off, though, is that instead of getting the applicationId conveniently from the spark session, we need to parse the spark-submit process’ output and extract the applicationId.
A naiive approach would be to print the applicationId from the spark session to pass it to the shell script. But the only way to do so is by printing the applicationId, and in cluster mode, this would go to the stdout of another machine in the cluster, which we cannot access from the driver server.
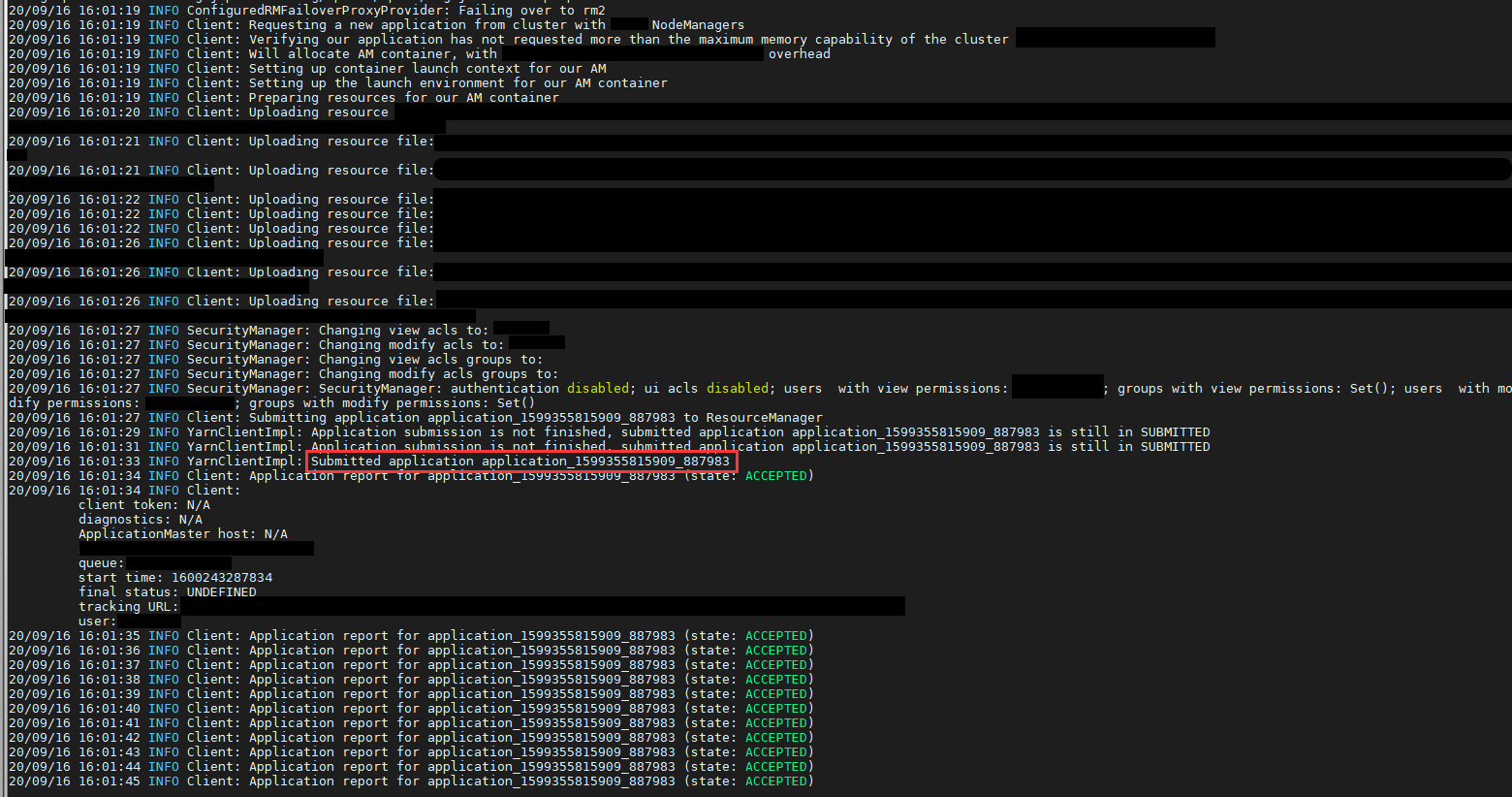
After some digging, we found anoter way to get the applicationId. In cluster mode, the spark-submit command is launched by a client process, which runs entirely on the driver server. The log of this client process contains the applicationId, and this log - because the client process is run by the driver server - can be printed to the driver server’s console. In other words, this is the only place where the shell script can access the spark job’s applicationId.
Implementation

Print client process log to console
- Add a log4j.properties file as follows. AS shown above, the applicationId in the client process’ log is INFO level. So we need to set log4j.logger.Client to INFO level.
log4j.rootLogger=INFO, stdout, stderr log4j.logger.Client = INFO, stdout, stderr - Pass the above log4j.properties file to the
SPARK_SUBMIT_OPTSof the driver server that runs the client process. This gets the client process’ log to be printed to the driver server’s console.SPARK_SUBMIT_OPTS="-Dlog4j.debug=true -Dlog4j.configuration=file://${ROOT}/xxx/config/log4j.properties" \ spark-submit \ --queue ${QUEUE} \ --deploy-mode cluster \ --master yarn \ --name "${sparkAppName}" \ ${sparkConfig} \ --py-files ${ROOT}/xxx/common.zip,${ROOT}/xxx/${FOLDER_NAME}/${FOLDER_NAME}_config.py,${ROOT}/xxx/${FOLDER_NAME}/${FOLDER_NAME}_logic.py \ ${ROOT}/xxx/xxx/${FOLDER_NAME}/${SCRIPT_NAME}.py ${param}
Parse client process log to get applicationId
- Launch the client process via
run. - Set trap for the interruption signals SIGINT, SIGTERM to kill the application upon receiving termination signals SIGINT (Ctrl-C) and SIGTERM (Airflow mark success/kill).
- Note that Airflow has its own catch and cleanup mechanism for SIGTERM. So unless our Airflow can be customized, marking success/killing tasks on Airflow would not trigger our cleanup mechanism detailed below.

- Read the client process’ log line by line to extract the applicationId.
#!/bin/bash
# constants
if [[ ${USER} =~ "xxx" ]]
then
ROOT_HDFS="/user/xxx"
ROOT="/home/xxx"
QUEUE="xxx"
else
ROOT_HDFS="/user/${USER}"
ROOT="/ldap_home/${USER}"
QUEUE="regular"
fi
FOLDER_NAME=$(basename $(dirname $(realpath $BASH_SOURCE)))
SCRIPT_NAME=$(basename $BASH_SOURCE .sh)
param=${@}
sparkAppName="XXX - XXX ${param}"
sparkConfig=$(cat <<-END
--num-executors 100 \
--conf spark.executor.memoryOverhead=5G \
--conf spark.yarn.maxAppAttempts=1
END
)
run() {
SPARK_SUBMIT_OPTS="-Dlog4j.debug=true -Dlog4j.configuration=file://${ROOT}/xxx/config/log4j.properties" \
spark-submit \
--queue ${QUEUE} \
--deploy-mode cluster \
--master yarn \
--name "${sparkAppName}" \
${sparkConfig} \
--py-files ${ROOT}/xxx/common.zip,${ROOT}/xxx/xxx/${FOLDER_NAME}/${FOLDER_NAME}_config.py,${ROOT}/xxx/xxx/${FOLDER_NAME}/${FOLDER_NAME}_logic.py \
${ROOT}/xxx/xxx/${FOLDER_NAME}/${SCRIPT_NAME}.py ${param}
}
# helper functions
source "${ROOT}/xxx/common/shell_functions.sh"
APPLICATION_ID=""
# prepare to kill application via YARN upon receiving SIGINT (Ctrl-C), SIGTERM (Airflow) signals
trap 'kill_app ${APPLICATION_ID}' SIGINT SIGTERM # use single quotes to delay variable expansion till when the function is called
trapExit=$?
# read output of run() line by line to find applicationId
while read -r line; do
echo "${line}"
if [[ ${line} =~ "Submitting application application_" ]]
then
APPLICATION_ID=$(echo ${line} | grep -oP "application_[0-9_]*") # extract applicationId
echo "Found applicationId: ${APPLICATION_ID}, continue running..."
fi
done < <(run 2>&1)
get_application_status ${APPLICATION_ID}
sparkSubmitExit=$?
...
where shell_functions.sh include:
#!/bin/bash
...
exit_with_code() {
exitCode=$1
echo "Exiting with code $exitCode."
exit ${exitCode}
}
kill_app() {
echo "Received termination signal."
applicationId=$1
if [[ ${applicationId} != "" ]]
then
yarn application -kill ${applicationId}
return 1 # still need to collect log, cannot exit yet
else
echo "Application not yet submitted. Skipping kill via YARN..."
exit_with_code 1 # no need to collect log, can directly exit
fi
}
get_application_status() {
applicationId=$1
status=$(yarn application -status ${applicationId} 2>&1)
echo "${status}"
if [[ ${status} =~ "Final-State : SUCCEEDED" ]]
then
return 0
else
return 1
fi
}
Collect YARN aggregated logs to designated directory upon job completion
Use the extracted applicationId to collect logs to designated directory after the application is finished.
#!/bin/bash
...
# directory to store logs
LOG_DIR="${ROOT}/logs/${FOLDER_NAME}"
mkdir -p ${LOG_DIR}
# construct name of log file from parameters
logFileName="${SCRIPT_NAME} ${param}"
logFileName=${logFileName// /_}
logFileName=${logFileName//\/-}
# collect aggregated logs to designated directory
sleep 5
collect_log "${APPLICATION_ID}" "${LOG_DIR}/${logFileName}.txt" 10 3
collectLogExit=$?
# exiting
finalExit=$((${trapExit}+${sparkSubmitExit}+${collectLogExit}))
echo "trapExit = ${trapExit}, sparkSubmitExit = ${sparkSubmitExit}, collectLogExit = ${collectLogExit}"
exit_with_code ${finalExit}
where shell_functions.sh include:
#!/bin/bash
collect_log_helper() {
applicationId=$1
logPath=$2
echo "Collecting log..."
output=$(yarn logs -applicationId ${applicationId} -log_files stdout stderr -am 1 2>&1)
status=$(yarn application -status ${applicationId} 2>&1)
echo "${status}"
if [[ "$output" =~ "Can not find" ]] || [[ "$output" =~ "Unable to get" ]] || [[ "$output" =~ "File "+[a-z0-9\/\_]*+"${applicationId} does not exist." ]] # log aggregation not ready yet
then
echo "${output}"
if [[ "${status}" =~ "Log Aggregation Status : NOT_START" || "${status}" =~ "Log Aggregation Status : N/A" ]]
then
echo "Log aggregation not started. Skipping log collection..." # usually because log is not generated, e.g., application was killed before it started runnning
return 0
elif [[ ${status} =~ "Log Aggregation Status : DISABLED" ]]
then
echo "Log aggregation disabled. Skipping log collection..."
return 0
elif [[ ${status} =~ "Log Aggregation Status : TIME_OUT" ]]
then
echo "Log aggregation time out. Aborting..."
return -1
else
if [[ ${status} =~ "State : FINISHED" ]]
then
echo "Log collection failed. Waiting for retry..."
return 2 # unlimited retry if spark job finished, because in this case it must have stdout/stderr log in the driver container
# Note: retry is only truly unlimited if there is no error, the process will still terminate upon exception, e.g., YARN's log size limit error
else
echo "Log aggregation incomplete. Waiting for retry..."
return 1 # application not in FINISHED status (possibly killed and may not have logs), limited retry
fi
fi
else
# echo "yarn logs -applicationId ${applicationId} --size_limit_mb -1 -log_files stdout stderr -am 1 | hadoop fs -appendToFile - ${logPath}"
# yarn logs -applicationId ${applicationId} --size_limit_mb -1 -log_files stdout stderr -am 1 | hadoop fs -appendToFile - ${logPath}
echo "yarn logs -applicationId ${applicationId} --size_limit_mb -1 -log_files stdout stderr -am 1 |& tee -a ${logPath}"
# (yarn logs -applicationId ${applicationId} --size_limit_mb -1 -log_files stdout stderr -am 1 |& tee -a $logPath) >/dev/null # do not print log
yarn logs -applicationId ${applicationId} --size_limit_mb -1 -log_files stdout stderr -am 1 |& tee -a ${logPath} # print log
statuses=( "${PIPESTATUS[@]}" ) # copy PIPESTATUS to array statuses
yarnCmdStatus=${statuses[$(( ${#statuses[@]} - 2 ))]}
hadoopCmdStatus=${statuses[$(( ${#statuses[@]} - 1 ))]}
if [[ ${yarnCmdStatus} -eq 0 && ${hadoopCmdStatus} -eq 0 ]]
then
return 0
else
return 1
fi
fi
}
collect_log() {
applicationId=$1
if [[ ${applicationId} != "" ]]
then
logPath=$2
retryInterval=30
maxRetryNo=5
collect_log_helper ${applicationId} ${logPath}
RET=$?
if [[ ${RET} -eq -1 ]]
then
echo "Log collection failed. Aborting..."
else
while [[ (${RET} -eq 2) || (${RET} -eq 1 && ${maxRetryNo} -gt 0) ]]; do
echo "Log collection failed, retrying in ${retryInterval} seconds..."
sleep ${retryInterval}
collect_log_helper ${applicationId} ${logPath}
RET=$?
maxRetryNo=$((maxRetryNo-1))
done
if [[ ${RET} -eq 1 && ${maxRetryNo} -eq 0 ]]
then
echo "Maximum number of retries reached. Aborting log collection..."
return 1
else
return ${RET}
fi
fi
else
echo "No applicationId. Skipping log collection..." # technically this won't happen
return 0
fi
}
...
Workflow
YARN’s spark application statuses are:

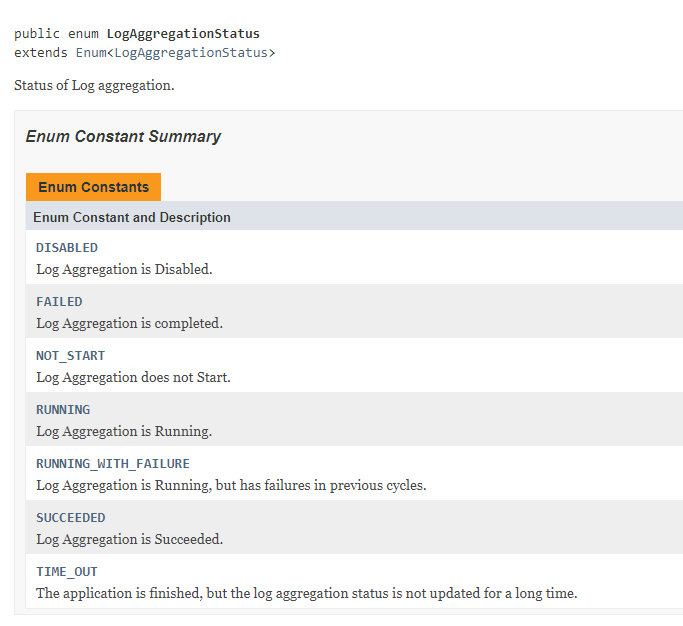
YARN’s log aggregation statuses are:
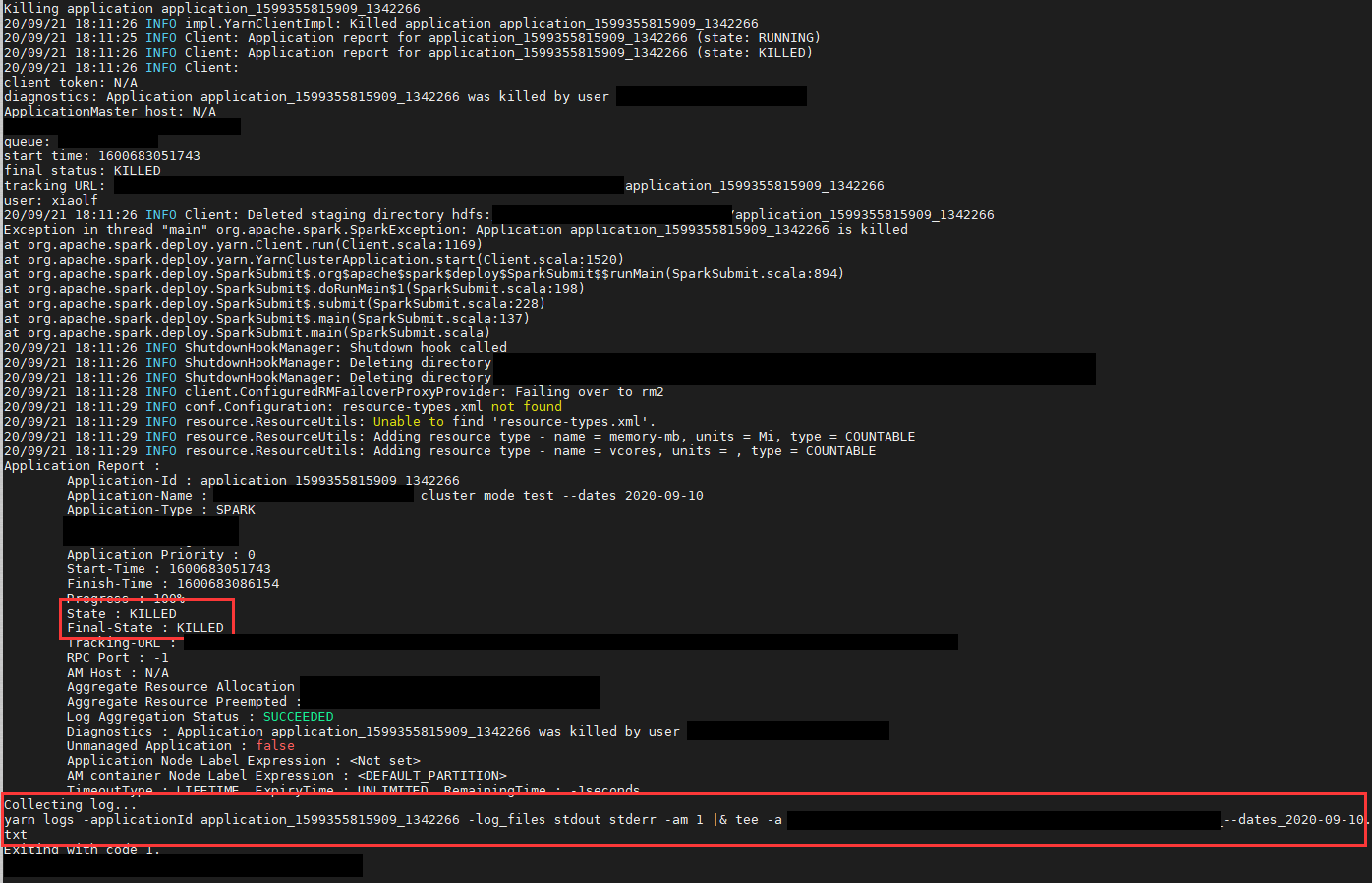
When the spark application terminates normally or upon exception, collect_log will be triggered to copy the logs aggregated by YARN to a designated directory.
What to do when the spark application is killed, on the other hand, requires extra handling.
If the job is killed before reaching SUBMITTED status
kill_appwon’t be invoked as the spark application is not yet launched;collect_logwon’t be triggered as no log is generated.
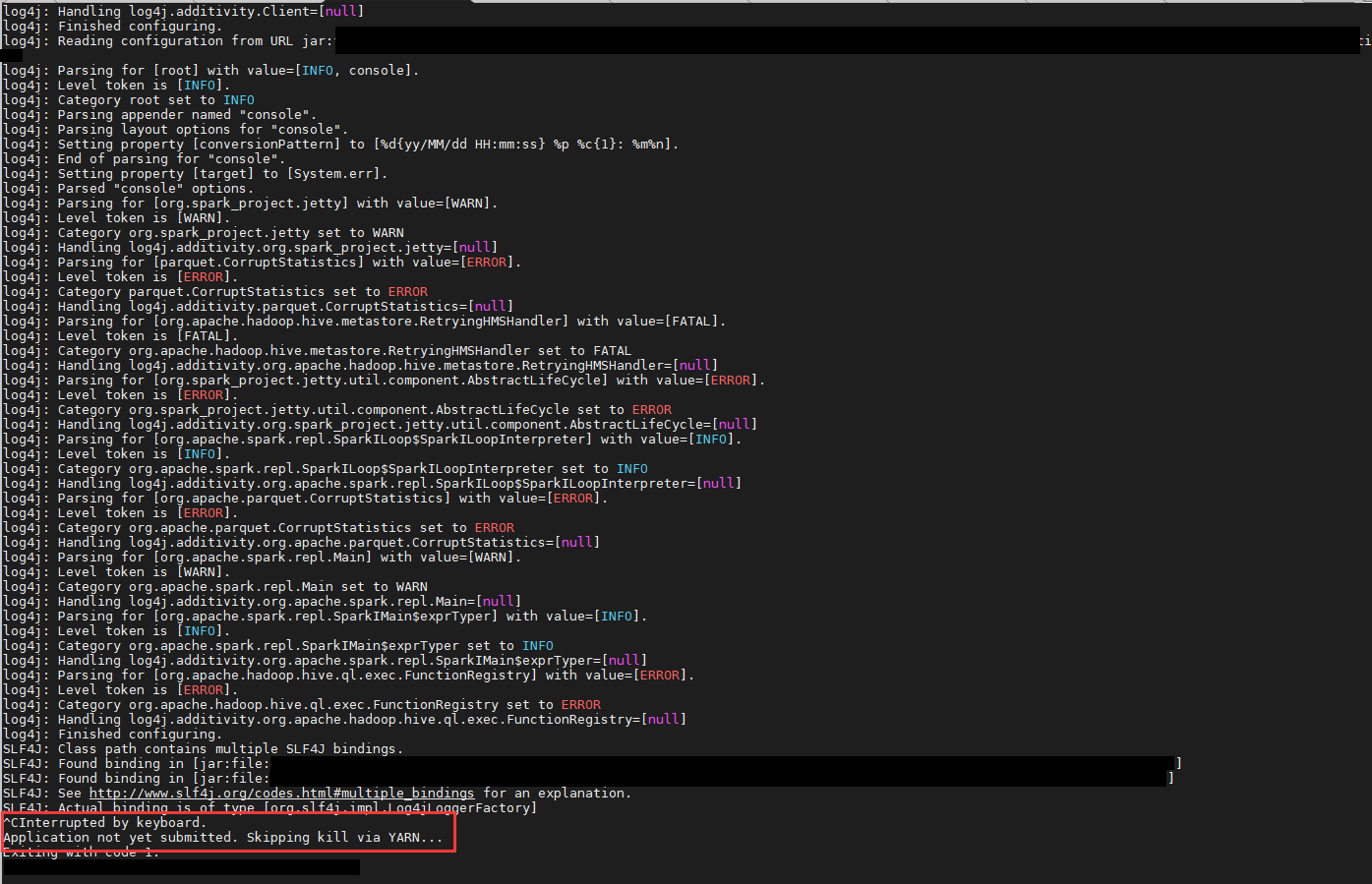
If the job is killed in or after SUBMITTED status but before reaching RUNNING status
kill_appwill be invoked to kill the application before eventually exiting from the client process;collect_logwon’t be triggered as no log is generated.
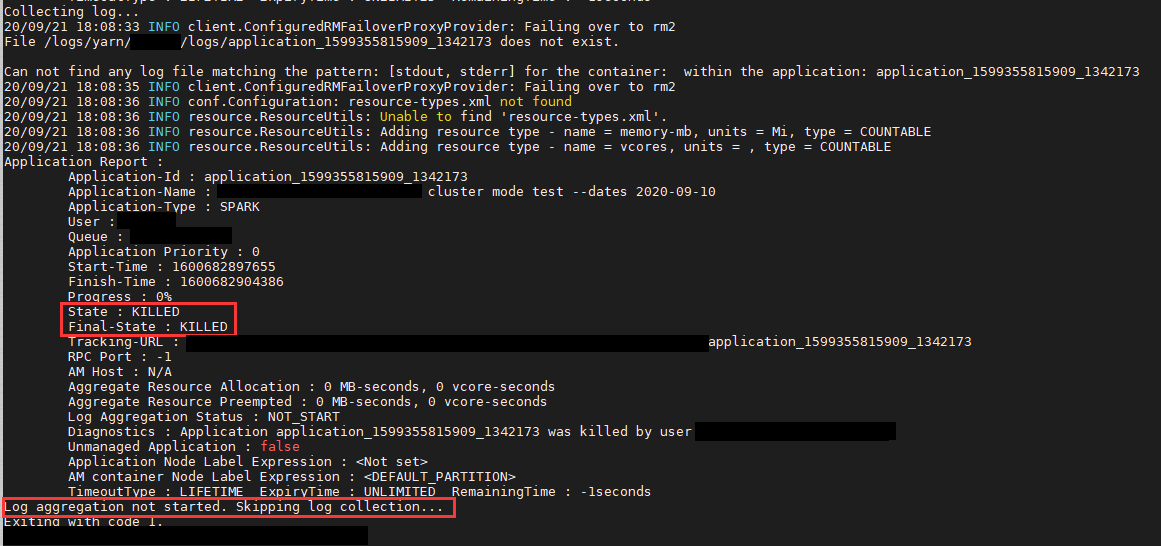
If the job is killed after RUNNING status
kill_appwill be invoked to kill the application before eventually exiting from the client process;collect_logwill be triggered to collect the YARN aggregated logs after the application is killed.