I want to use PySpark form Jupyter Notebook for covenient view of program output.
Preparation
This post assumes configurations in this earlier post. I read this article.
Method
There are two ways to set up PySpark with Jupyter Notebook. They are explained in detail in the article above. I would like to supplement the article by providing a summary and highlighting some caveats.
Option 1: Open notebook directly from PySpark
- Create environment variables
PYSPARK_DRIVER_PYTHONandPYSPARK_DRIVER_PYTHON_OPTSand set them to bejupyterand'notebook', respectively. - Open
cmdand typepyspark, this should open Jupyter Notebook in the browser. - Run the following code in the notebook. (
sample.txtis taken from the wikipedia page of Apache Spark.)import random num_samples = 100000000 def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, num_samples)).filter(inside).count() pi = 4 * count / num_samples print(pi) lines = sc.textFile("sample.txt") print(lines.count()) print(lines.first())The output should look like this.
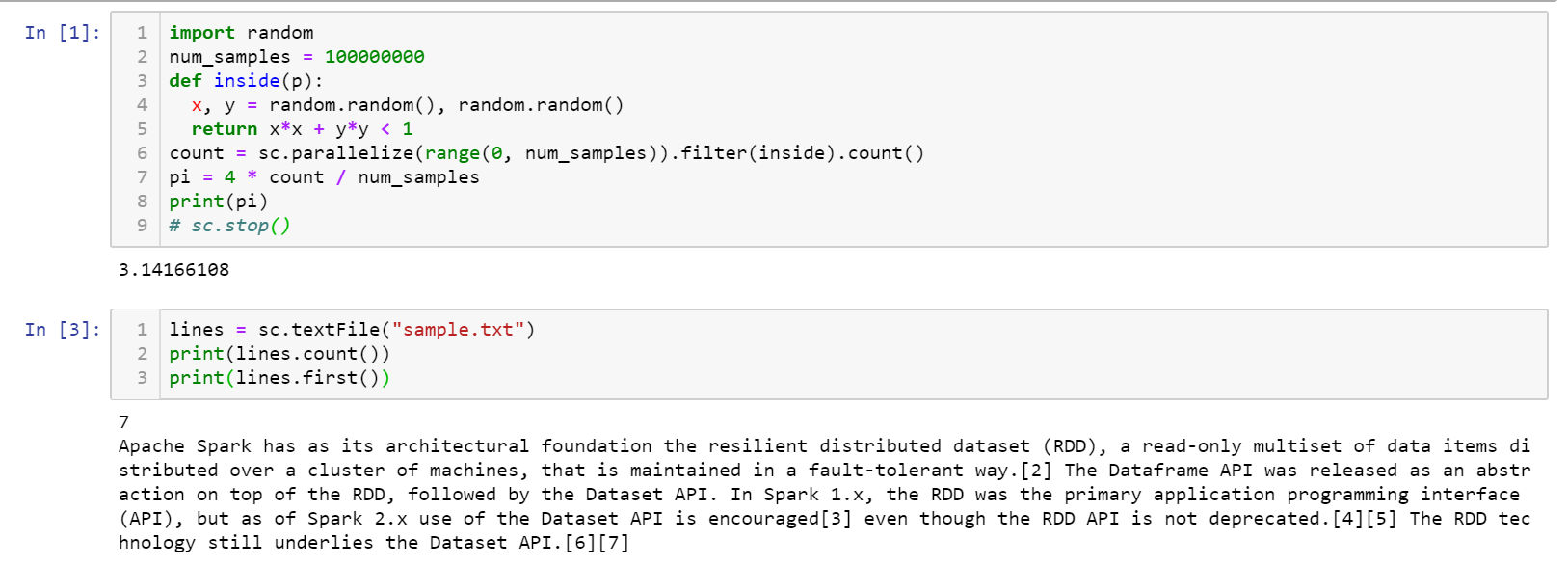
Option 2: Invoke Spark environment in notebook on the fly
- Install
findsparkmodule by typingpip install findspark. - Create environment variable
SPARK_HOMEand set it to the path of Spark installation. - Launch Jupyter Notebook.
- Paste the following code at the start of the notebook.
import findspark findspark.init() import pyspark - Run the following code.
import random sc = pyspark.SparkContext() num_samples = 100000000 def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, num_samples)).filter(inside).count() pi = 4 * count / num_samples print(pi) sc.stop() sc = pyspark.SparkContext() lines = sc.textFile("sample.txt") print(lines.count()) print(lines.first()) sc.stop()The output should look like this.
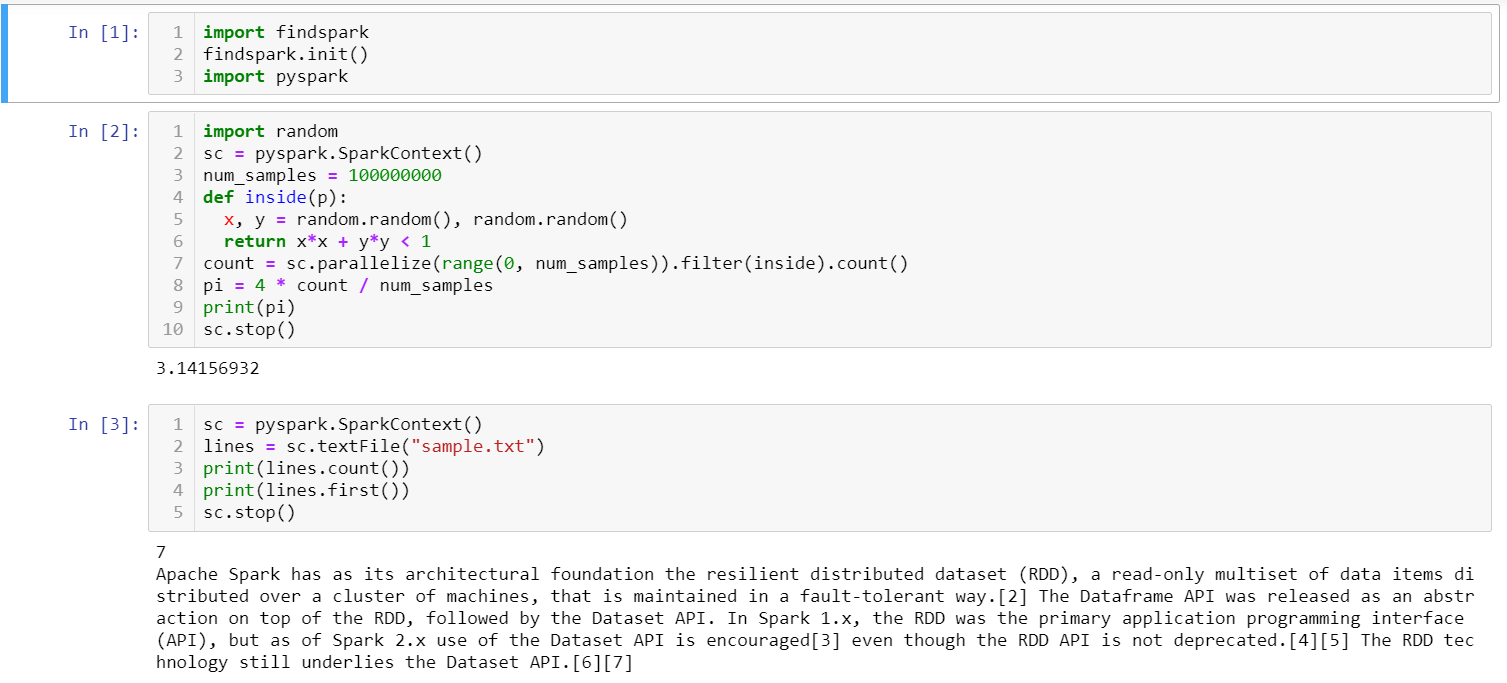
Note that option 1 does not require manually creating a SparkContext object, while option 2 does. As a result, if the notebook created in option 1 is not opened from PySpark but from a regular Jupyter Notebook, the sc variable would not be recognized. Vice versa, if the notebook created in option 2 is opened from PySpark, the line sc = pyspark.SparkContext() would be redundant, and the program would raise an error saying that only one SparkContext can be run at once.