I came across this motion comic (click here for the video if the link does not work) based on issue 16 of the IDW comic The Transformers: More than Meets the Eye (click here to view the comic in Russian or English and here to view in Chinese).
In the motion comic, a video message is composed by putting together footage from various videos. I wanted to do the same with the image dimension, i.e., compose an image message by putting together various cropped images from the comics in a Montage-ish manner, as shown below. To read the message, just read off the speech bubbles in each image from left to right and top to down.

Preparation
I read this article about the OCR engine Tesseract and this one about OpenCV.
Method
Suppose we have a text message and a folder of comic images. To compose the image message, for each word in the text message, we need to find a comic page with a text bubble that contains that word, crop it, and put all the cropped images together. Cropping and putting the cropped images together are steps that can be done manually in photoshop in a reasonably straightforward manner. The step that is not a reasonable manual task is finding a comic page that contains a certain word. This is where optical character recognition (OCR) comes in.
OCR is the conversion of images of text into machine-encoded text. We will use it to extract text from the comics’ speech bubbles. We can then store the text along with the paths of the corresponding comic pages to make a text-path dictionary. In this way, when we need a comic page that contains a certain word, we can simply search for the word in this dictionary and look up the path of the comic page that contains it. E.g., with the following dictionary, if we need the word “machine”, searching for it would lead us to line 3, and we would know to view the comic page at C:/comics/issue01/page02.jpg.
| path | text |
|---|---|
| C:/comics/issue01/page01.jpg | I DON’T LIKE IT… |
| C:/comics/issue01/page01.jpg | CAN’T WE JUST PUSH A BUTTON AND BE DONE WITH IT? |
| C:/comics/issue01/page02.jpg | EACH A COG IN THE GREAT MACHINE. |
| … | … |
All code can be found here.
OCR with Tesseract
For the above purpose, we will use the OCR engine Tesseract.
- Download Tesseract from here.
- Add the path of installation, e.g.,
C:\Program Files (x86)\Tesseract-OCR, to environment variables. -
Open cmd and type
tesseract -v. If the version information shows up, the installation is successful. E.g.,C:\Users\largecats>tesseract -v tesseract 3.05.01
Image processing with OpenCV
Tesseract works best with images of text with clean background. Since a comic page contains image and text, it does not make sense to pass the entire page to Tesseract and expect it to recognize the text scattered in speech bubbles. Thus, we need to preprocess the comic page, isolate the candidate speech bubbles, crop them from the comic page, and feed each cropped speech bubble candidate to Tesseract for character recognition.
We begin by importing the necessary modules.
import cv2
import numpy as np
from matplotlib import pyplot as plt
import pytesseract
import os
import csv
Detecting speech bubbles
First of all, we need to find all (or as many as possible) speech bubbles in a given comic page. Luckily, speech bubbles usually have relatively well-defined edges and mostly rectangular shapes. To exploit these properties in detecting speech bubbles, we use the findContours() function from cv2 to recognize edges in the comic page and bound them using rectangles (boundingRect()), which would then become the speech bubble candidates. As shown below, findContours() picks up a lot of noise that are not speech bubbles.

Luckily, speech bubbles have a small range of sizes. Thus, we can filter out the candidates that are unlikely to be speech bubbles because they are either too large or too small, as shown below.

To help with contour detection, before the steps above, we turn the image into gray scale, filter out noise, and add some filters to make the edges sharper. For convenice, we define the following function to do all the above. The function returns a list of candidate speech bubbles as images.
# find all speech bubbles in the given comic page and return a list of cropped speech bubbles (with possible false positives)
def findSpeechBubbles(imagePath, method = 'simple'):
# read image
image = cv2.imread(imagePath)
# gray scale
imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# filter noise
imageGrayBlur = cv2.GaussianBlur(imageGray,(3,3),0)
if method != 'simple':
# recognizes more complex bubble shapes
imageGrayBlurCanny = cv2.Canny(imageGrayBlur,50,500)
binary = cv2.threshold(imageGrayBlurCanny,235,255,cv2.THRESH_BINARY)[1]
else:
# recognizes only rectangular bubbles
binary = cv2.threshold(imageGrayBlur,235,255,cv2.THRESH_BINARY)[1]
# find contours
contours = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)[1]
# get the list of cropped speech bubbles
croppedImageList = []
for contour in contours:
rect = cv2.boundingRect(contour)
[x, y, w, h] = rect
# filter out speech bubble candidates with unreasonable size
if w < 500 and w > 60 and h < 500 and h > 25:
croppedImage = image[y:y+h, x:x+w]
croppedImageList.append(croppedImage)
return croppedImageList
Somehow, images cropped this way (via the image[y:y+h, x:x+w] syntax) are not as good for OCR as images cropped using external programs, such as QQ. But I did not figure out a way to use external programs to crop the images and feed it to the OCR engine, so this would have to be a game of another day.
Feeding speech bubbles to Tesseract
Now, suppose we have a speech bubble candidate. We need to feed it to Tesseract for (English) character recognition. pytesseract.image_to_string() returns the recognized characters as a string. We filter for characters that do show up in the comics.
# apply the ocr engine to the given image and return the recognized script where illegitimate characters are filtered out
def tesseract(image):
script = pytesseract.image_to_string(image, lang = 'eng')
for char in script:
if char not in ' -QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm,.?!1234567890"":;\'':
script = script.replace(char,'')
return script
The script produced by Tesseract from the comic page above is as follows.
I DONT LIKE IT...
"THE LAW 54? THISSORT 0F THING HA6 TOBE DECLARE? ON-GITE.FORrMLTIEG.
I DONT HNDERSTAND WHYWE HAVE TO BE HERE. CANTWE JNST... PUSH A BHTTONAND BE DONE WITH IT?
MINING OUTPOST C-12.
LONG AGO. PEACETMIE.
THE CYBERTQON SYSTEM.1
The character recognition is not perfect, but acceptable.
File I/O
We define the following helper functions. looper() loops through the root directory that contains the comics and returns a list of paths of the comic pages. Ideally the root directory should have a structure like this:
root
+-- issue01
+-- page01.jpg
+-- page02.jpg
+-- ...
+-- issue02
+-- page01.jpg
+-- page02.jpg
+-- ...
...
Note that the code only picks up .jpg, .png, and .bmp files from (folders and subfolders of) the root directory. write_script_to_csv()writes the detected comic script along with the path of the corresponding comic page to a .csv file.
# loop through each file in the given directory, not including zip files
def looper(rootDir):
fileNameList = []
filePathList = []
for subDir, dirs, files in os.walk(rootDir):
for file in files:
fileInfo = file.split('.')
fileName, fileExten = fileInfo[0], fileInfo[-1]
filePath = os.path.join(subDir, file)
if fileExten == 'jpg' or fileExten == 'png' or fileExten == '.bmp':
# if fileExten != 'zip':
if fileName not in fileNameList:
fileNameList.append(fileName)
filePathList.append(filePath)
return filePathList
# append image path and script to the output csv file
def write_script_to_csv(imagePath, script, outputFilePath):
with open(outputFilePath, 'a', encoding = "utf-8", newline = "") as f:
writer = csv.writer(f)
newRow = [imagePath, script]
writer.writerow(newRow)
Main loop
The main work is done as follows. For each comic page in the root directory, we find the speech bubbles, feed them to Tesseract after some further denoising and processing, obtain the comic script, and write it dynamically to a .csv file along with the comic page path.
# initialize output file
with open(outputFilePath, 'w',newline = "") as f:
writer = csv.writer(f)
writer.writerow(['filePath', 'script'])
# for each image in the given directory, process each speech bubble found and feed it to the ocr engine
for imagePath in looper(rootDir):
print(imagePath)
# find speech bubbles in each image
try:
croppedImageList = findSpeechBubbles(imagePath, method = 'simple')
except:
continue
scriptList = []
for croppedImage in croppedImageList:
# enlarge
croppedImage = cv2.resize(croppedImage, (0,0), fx = 2, fy = 2)
# denoise
croppedImage = denoise(croppedImage, 2)
kernel = np.ones((1, 1), np.uint8)
croppedImage = cv2.dilate(croppedImage, kernel, iterations = 50)
croppedImage = cv2.erode(croppedImage, kernel, iterations = 50)
# turn gray
croppedImageGray = cv2.cvtColor(croppedImage, cv2.COLOR_BGR2GRAY)
# Gaussian filter
croppedImageGrayBlur = cv2.GaussianBlur(croppedImageGray,(5,5),0)
# edge detection
croppedImageGrayBlurLaplacian = cv2.Laplacian(croppedImageGrayBlur,cv2.CV_64F)
# adjust contrast and brightness
croppedImageGrayBlurLaplacian = np.uint8(np.clip((10 * croppedImageGrayBlurLaplacian + 10), 0, 255))
# pass cropped image to the ocr engine
script = tesseract(croppedImageGrayBlurLaplacian)
if script != '' and script not in scriptList:
scriptList.append(script)
print(script)
# append image path and script to the output csv file
write_script_to_csv(imagePath, script, outputFilePath)
Result
The resulting data file looks like this:
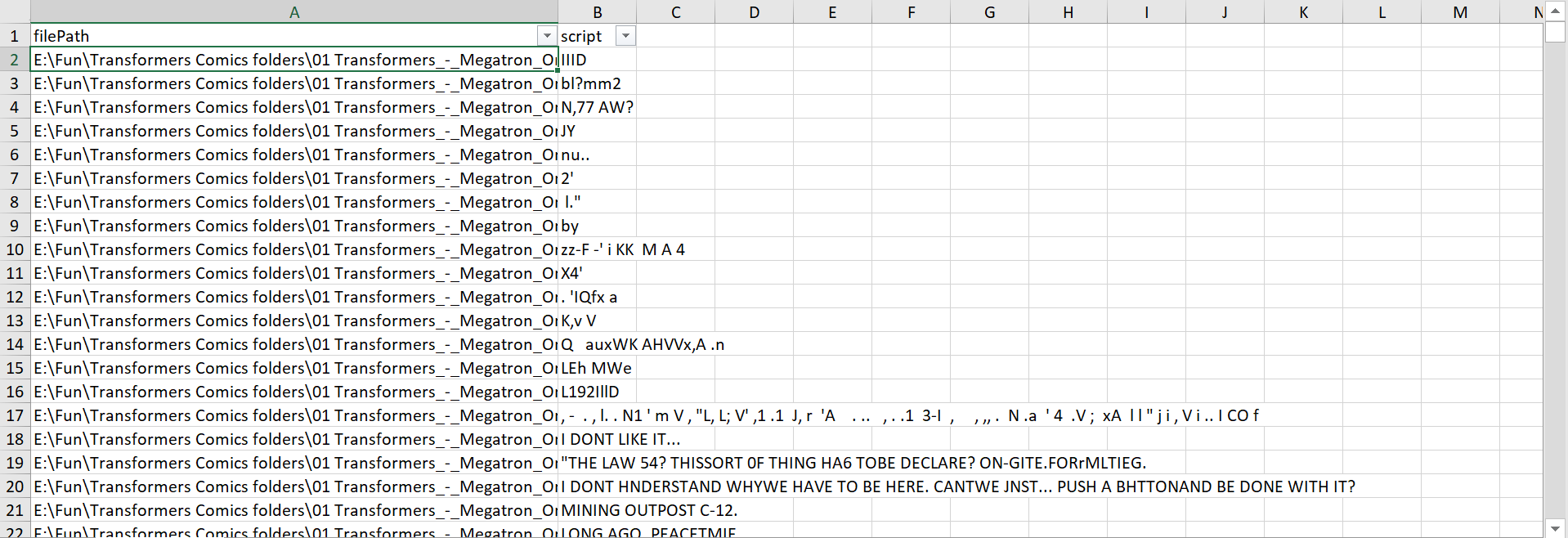
There are still noises, but at least most of the comic script are picked up reasonably well. This is enough for our purpose, since we technically only need a relatively small number of sparsely distributed individual words that are correctly recognized.