When Bumblebee was released, I wanted to see what people would say about it and how its reception would compare with the other productions in the Transformers franchise.
Preparation
I read this article about NLTK and this documentation about a module for word cloud.
Method
All code can be found here.
Scraping movie reviews
Using techniques discussed here, I collected the IMDb reviews for Bumblebee and seven other productions in the franchise. The only difference is that there are more dynamic web content to deal with this time: There are many “load more” buttons on the web page that need to be clicked in order to see all the movie reviews. Luckily, this can be taken care of by the click() method of a button object made possible via Selenium, in a manner as follows.
# click "load more" to load all results until there is no more "load more" button
while True:
try:
loadMoreButton = browser.find_element_by_class_name('ipl-load-more__button')
loadMoreButton.click()
# wait for the next load more button to load; note that if the wait is too short, the next load button may not be clicked
time.sleep(10)
except:
break
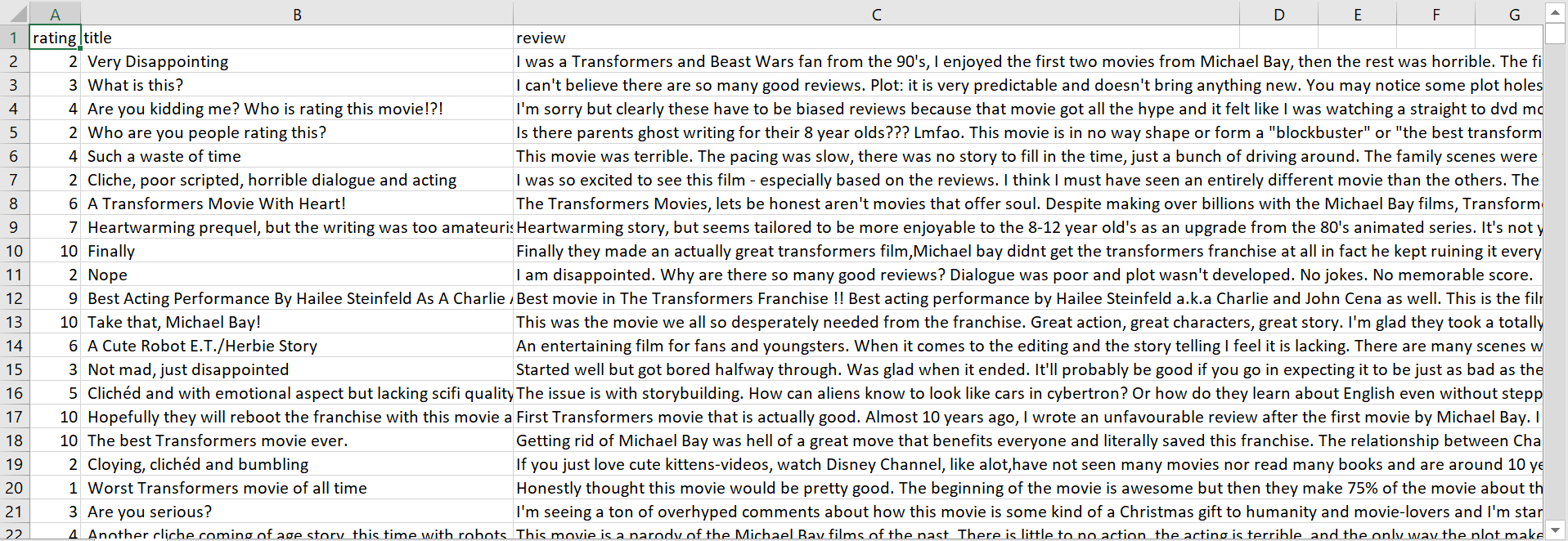
The resulting data file for the movie Bumblebee looks something like this:
Text analysis
Word cloud
I wanted to see what people say about the movie, so it makes sense to visualize the key words that appear in the reviews, e.g., via a word cloud. Both the reviews and their titles can be used as corpus. Their differences are discussed at the end of this section.
Pre-processing
Before making the visualization, the text needs to be pre-processed. We begin by importing the necessary modules.
import os
import nltk
import csv
import pandas as pd
import re
import random
import matplotlib.pyplot as plt
import numpy as np
After reading in the .csv file, we tokenize the text into individual words which are the units of analysis.
fileName = "reviews.csv"
df = pd.read_csv(fileName)
from nltk.tokenize import word_tokenize
tokenizedWords = []
for i in range(len(df.index)):
review = df['review'][i]
tokenizedWord = word_tokenize(review)
tokenizedWords.append(tokenizedWord)
tokenizedWords is now a list of lists of individual words or punctuation marks, e.g.,
[['I', 'was', 'a', 'Transformers', 'and', 'Beast', 'Wars', 'fan', 'from', 'the', '90', "'s", ',', 'I', 'enjoyed', 'the', 'first', 'two', 'movies', 'from', 'Michael', 'Bay', ',',
'then', 'the', 'rest', 'was', 'horrible', '.', 'The', 'first', '5', 'minutes', 'of', '*Bumblebee*', 'were', 'good', ',', 'then', 'its', 'goes', 'to', 'sh**', '.', '90', '%', 'of', 'the', 'movie', 'focuses', 'on', 'the', 'teenager', "'s", 'life', 'and', 'lame', 'complications', 'and', 'fears', '.', 'We', 'barely', 'see', 'some', 'action', 'from', '*Bumblebee*', ',', 'he', 'is', 'mostly', 'being', 'all', 'cuddly', 'and', 'acting', 'like', 'a', 'puppy', '.', 'Instead', 'of', 'focusing', 'on', 'the', 'origins', 'of', 'the', 'Transformers', 'and', 'Orion', 'Pax', ',', 'we', 'are', 'hear', 'watching', 'the', 'girl', 'being', 'bullied', 'for', 'not', 'taking', 'the', 'dive', '...', 'then', 'conveniently', 'having', 'to', 'take', 'the', 'dive', 'in', 'the', 'end', 'of', 'the', 'movie', 'to', '...', 'I', 'do', "n't", 'know', 'how', 'she', 'helps', '*Bumblebee*', 'underwater', '.', 'That', 'scene', 'on', 'the', 'road', 'where', 'she', 'aske', 'her', 'friend', 'to', 'take', 'off', 'his', 'shirt', 'to', 'just', 'wrap', 'it', 'around', 'her', 'head', 'and', 'scream', 'out', 'of', 'the', 'car', '...', 'when', 'she', 'is', 'clearly', 'wearing', 'a', 'shirt', 'over', 'a', 't-shirt', '...', 'stupid..', 'That', 'Salute', 'sign', 'from', 'Cena', 'at', 'the', 'end..', 'I', 'felt', 'like', 'i', 'was', 'watching', 'a', 'combination', 'of', 'Mighty', 'Joe', 'Young', 'and', 'Herbie', 'Reloaded', '.', 'Horrible..'], ...]
Since the units of analysis are words, there is no need to keep the list of lists structure, and so we merge these lists into one list.
words = []
for tokenizedWord in tokenizedWords:
for word in tokenizedWord:
words.append(word)
Next, we remove the stop words and punctuation marks from this list of words, while turning all remaining words into lower-case.
# remove stop words and punctuations
from nltk.corpus import stopwords
punctuations = ['.', ',', ';', ':', '!', '?']
stopWords = set(stopwords.words("english"))
filteredWords = []
for word in words:
if (word not in stopWords) and (word not in punctuations):
# turn into lower case
filteredWords.append(word.lower())
words = filteredWords
We also need to do lemmatization, that is, to “normalize” the words by restoring all variations (e.g., past tense, pural form) back to their original form. To do so, we first tag the words as verb, proposition, adjective, etc, and then convert them to their original forms accordingly. E.g., “movies” becomes “movie”, “watched” becomes “watch”.
# pos Tagging
tags = nltk.pos_tag(words)
# lemmatization
from nltk.stem.wordnet import WordNetLemmatizer
lem = WordNetLemmatizer()
lemWords = []
for i in range(len(words)):
word = words[i]
tag = tags[i][1]
if tag == 'VB' or tag == 'VBP':
lemWord = lem.lemmatize(word, "v")
elif tag == "PRP":
lemWord = word
else:
lemWord = lem.lemmatize(word)
lemWords.append(lemWord)
Lastly, we remove some uninformative words whose presence do not mean much in the context of the text to be analyzed, e.g., the name of the movie, the franchise, etc.
# remove uninformative words
filteredWords = []
for lemWord in lemWords:
if lemWord not in ["movie", "film", "review", "spoiler", "transformer", "transformers", "n't", "age", "extinction", "dark", "moon", "last", "knight", "revenge", "fallen", "one", "episode", "series", "show", "season"]:
filteredWords.append(lemWord)
The word cloud can be created as follows. The mask can be customized.
# merge list of words into one string
text = ' '.join(filteredWords)
# create word cloud
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
def grey_color_func(word, font_size, position, orientation, random_state = None, **kwargs):
return "hsl(0, 0%%, %d%%)" % random.randint(60, 100)
# mask
mask = np.array(Image.open("BBB_poster.jpg"))
# generate word cloud image
wordcloud = WordCloud(mask = mask).generate(text)
# diplay image
plt.figure(figsize=(18,12))
plt.imshow(wordcloud.recolor(color_func = grey_color_func, random_state = 3), interpolation = 'bilinear')
plt.axis("off")
plt.savefig("review_wordcloud.png", format = "png")
plt.show()
Result
Below is a wordcloud of the reviews for Bumblebee, followed by that of the review titles.

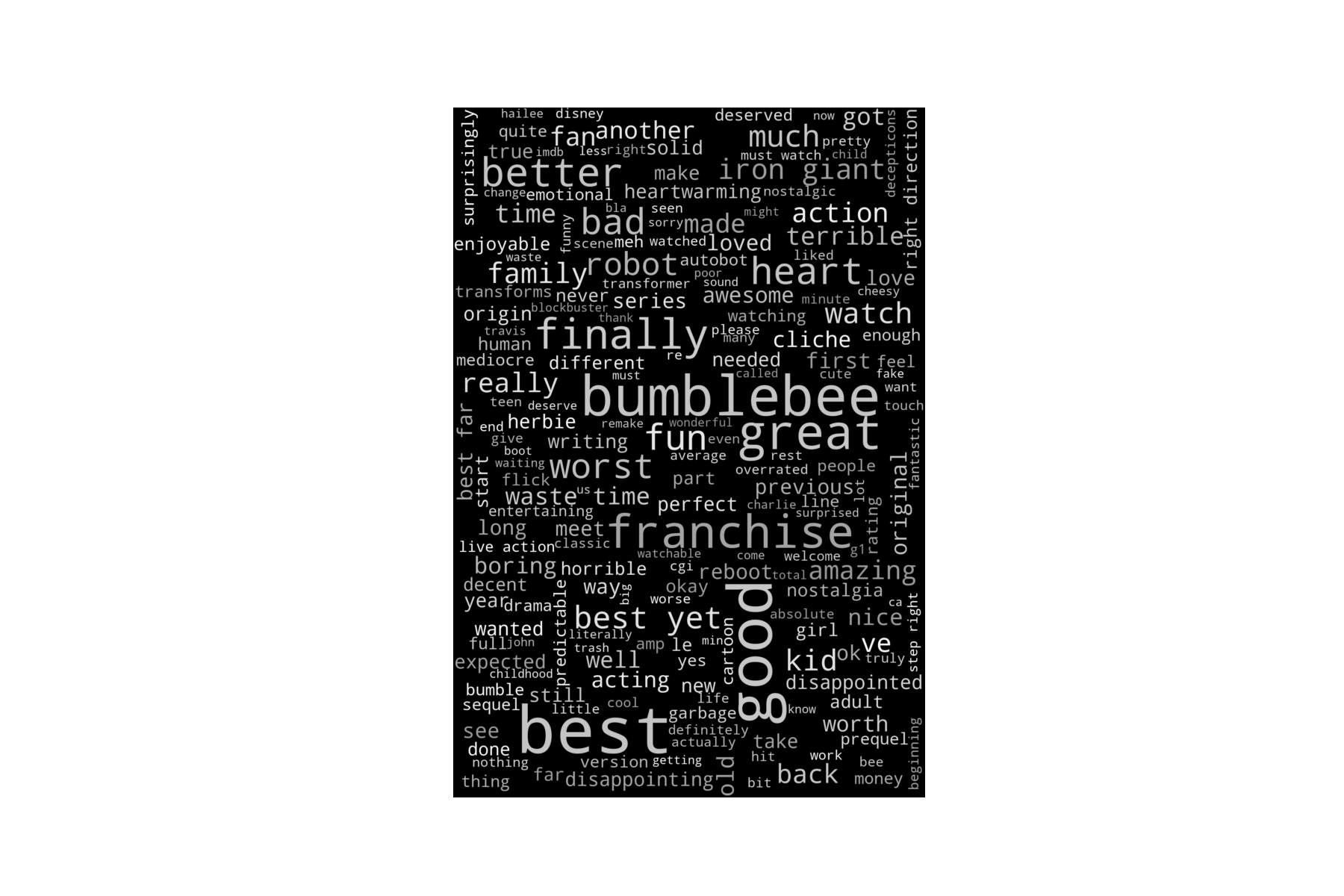
The wordcloud of the movie review titles seems to contain less noise, or uninformative words. This is expected as the reviews have not been filtered for words of importance using metrics such as the TF-IDF score. In light of this, I generated word clouds from the titles of movie reviews of some of the other movies in the franchise, listed below.







The trend is consistent with the IMDb ratings.
Sentiment analysis
To gain a quantitative sense of the movies’ receptions, I used NLTK’s sentiment analyzer, VADER, to compute a polarity score for the reviews. VADER seems to work best with short, casual contexts like twitter, as discussed here, so I used the review titles as corpus.
Pre-processing
We start by importing the necessary modules.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.tokenize import sent_tokenize
nltk.download('vader_lexicon')
Since sentences are now the units of analysis, we tokenize the review titles into sentences.
# tokenize into sentences
tokenizedSents = []
for i in range(len(df.index)):
review = df['title'][i]
tokenizedSent = sent_tokenize(review)
tokenizedSents.append(tokenizedSent)
# merge list of lists into one list
sents = []
for tokenizedSent in tokenizedSents:
for sent in tokenizedSent:
sents.append(sent)
The sentiment analyzer calculates a polarity score with 4 components, namely tendency towards negativity, positivity, neutrality, and overall tendency.
# polarity scores
neg = []
neu = []
pos = []
compound = []
sia = SentimentIntensityAnalyzer()
for sent in sents:
print(sent)
ps = sia.polarity_scores(sent)
print(ps)
neg.append(ps["neg"])
neu.append(ps["neu"])
pos.append(ps["pos"])
compound.append(ps["compound"])
scores = pd.DataFrame({'negative': neg, 'neutral': neu, 'positive': pos, 'compound': compound}, columns = ['negative', 'neutral', 'positive', 'compound'])
Polarity scores for some titles are shown below. The analyzer does not pick up the more layered sentiments, but overall, it seems to be doing ok.
Another Hollywood title destroyed by Chinese money
{'neg': 0.348, 'neu': 0.652, 'pos': 0.0, 'compound': -0.4939}
Best Transformers so far
{'neg': 0.0, 'neu': 0.417, 'pos': 0.583, 'compound': 0.6369}
IMDB's ratings are now a joke
{'neg': 0.0, 'neu': 0.645, 'pos': 0.355, 'compound': 0.296}
Bad writing
{'neg': 0.778, 'neu': 0.222, 'pos': 0.0, 'compound': -0.5423}
Lame
{'neg': 1.0, 'neu': 0.0, 'pos': 0.0, 'compound': -0.4215}
Rather watch Zoolader sequel than this!!!
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}
!
{'neg': 0.0, 'neu': 0.0, 'pos': 0.0, 'compound': 0.0}
Boring, predictable and stupid
{'neg': 0.74, 'neu': 0.26, 'pos': 0.0, 'compound': -0.6908}
Very bland
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}
Teen drama with terrible acting and plot holes
{'neg': 0.307, 'neu': 0.693, 'pos': 0.0, 'compound': -0.4767}
Story don't line up with the other movies
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}
Fast forward through the scenas
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}
What a waste of money!!
{'neg': 0.53, 'neu': 0.47, 'pos': 0.0, 'compound': -0.5242}
Result
Histograms of the polarity scores (compound) for the review titles of the 8 movies are shown below.
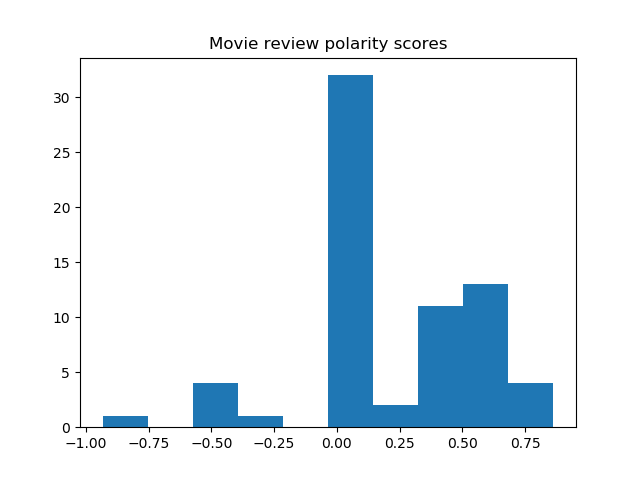
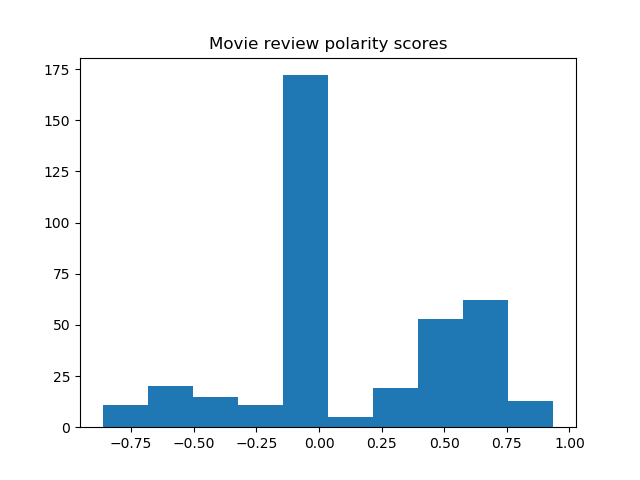
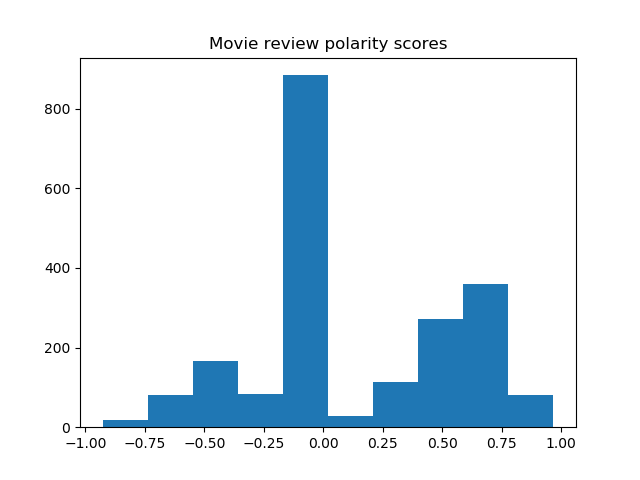
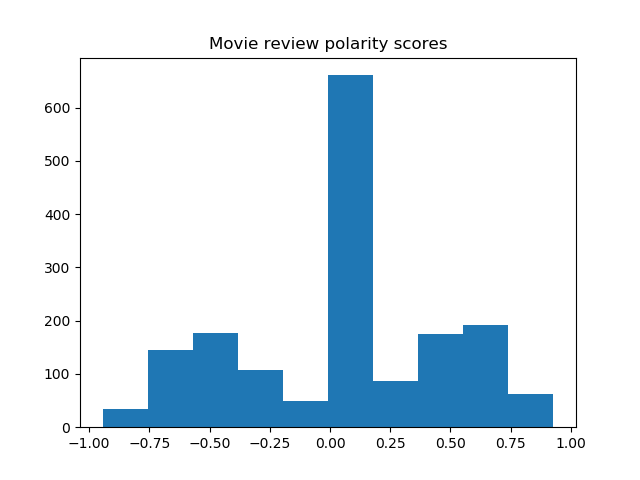
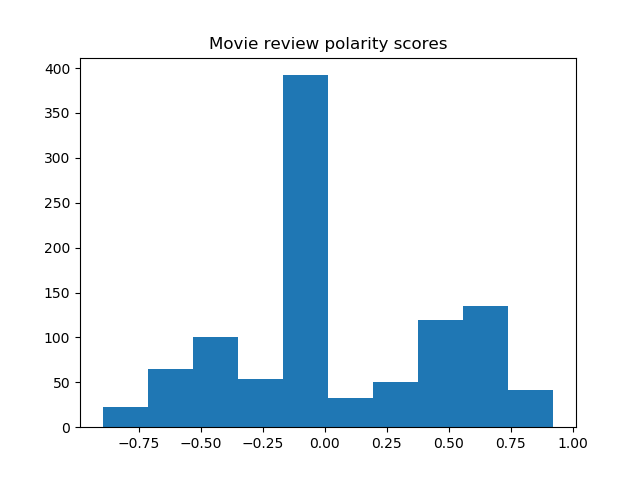
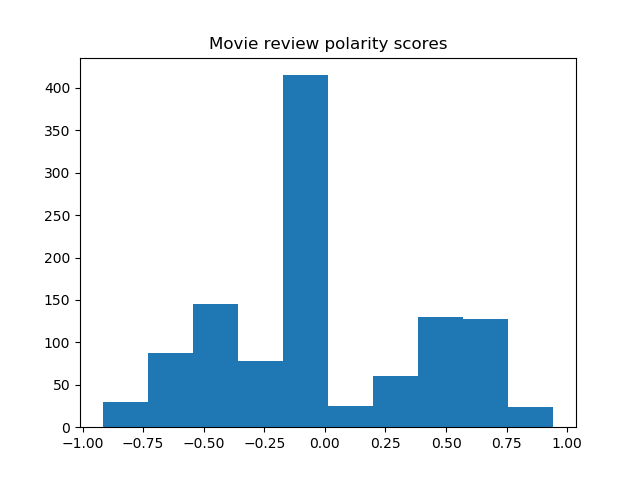
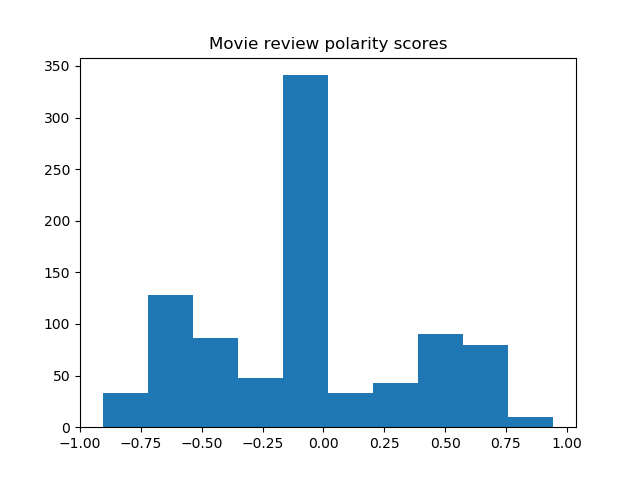
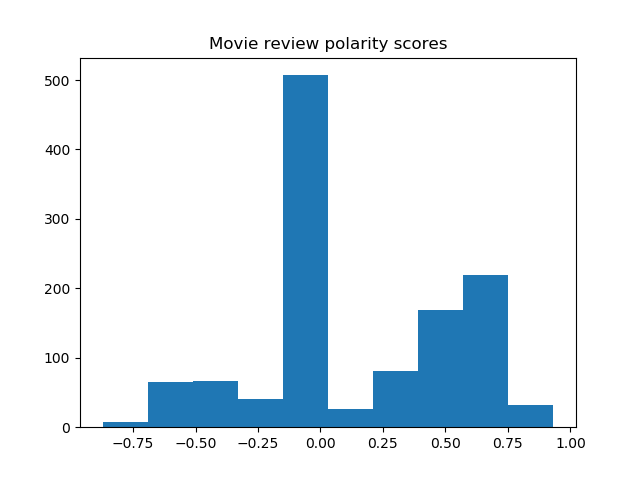
Most sentences are recognized as neutral, yet the trend of negative and positive tendencies seems to agree with the word clouds.