I wondered how movies at Douban compare to those at IMDb. I also wanted to learn web scraping as it was a required skill for a course I was going to take the following semester (otherwise I would have gone with API). So I decided to use web scraping to collect data on the top 250 movies at Douban and those at IMDb and do some comparative analyses.
Preparation
I read this article about BeautifulSoup.
Method
Douban and IMDb each has a list of top 250 movies. For each movie in Douban/IMDb’s list, I collected information of this movie from Douban/IMDb and IMDb/Douban. All code can be found here. However, kindly note that the code, data files, and graphs were produced in 2017, so some parts of the code may not work with the websites’ current configuration.
Collecting data
The information to be collected are movie title, year of release, genre, region, IMDb rating, and Douban rating.
Douban top 250 vs IMDb
Here are the top 250 movies on Douban. Note that there are 10 pages, with 25 movies per page. We start by importing the necessary modules:
import requests
from lxml import html
import re
import pandas as pd
import numpy as np
import time
import random
from bs4 import BeautifulSoup
from time import sleep
from random import randint
import os
We then loop through these 10 pages and scrape information of each movie on each page. We declare the following variables as preparation.
# scrape 10 pages, 25 movies per page
pages = [str(i) for i in range(0,10)]
# declare lists to store data
names = []
years = []
genres = []
imdbRatings = []
doubanRatings = []
regions = []
Now, for each page, we first make a get request using its url. This creates an object stored in the variable response, which allows us to obtain information we need about the page.
# for every page
for page in pages:
# make request
url = "https://movie.douban.com/top250?start=" + str(int(page)*25) + "&filter="
print(url)
response = requests.get(url)
Next, we pause the loop for a few seconds to avoid bombing the website with requests.
# pause loop to avoid bombarding the site with requests
sleep(random.randint(3, 5))
Then we parse the page we just obtained as html. This gives the html code of the page.
# parse page
pageHtml = BeautifulSoup(response.text, 'html.parser')
One can also view the html code directly from the browser. E.g., in chrome, just right-click and select “Inspect” (alternatively, Ctrl-Shift-I), and the page html code is in “Elements”, as shown below.
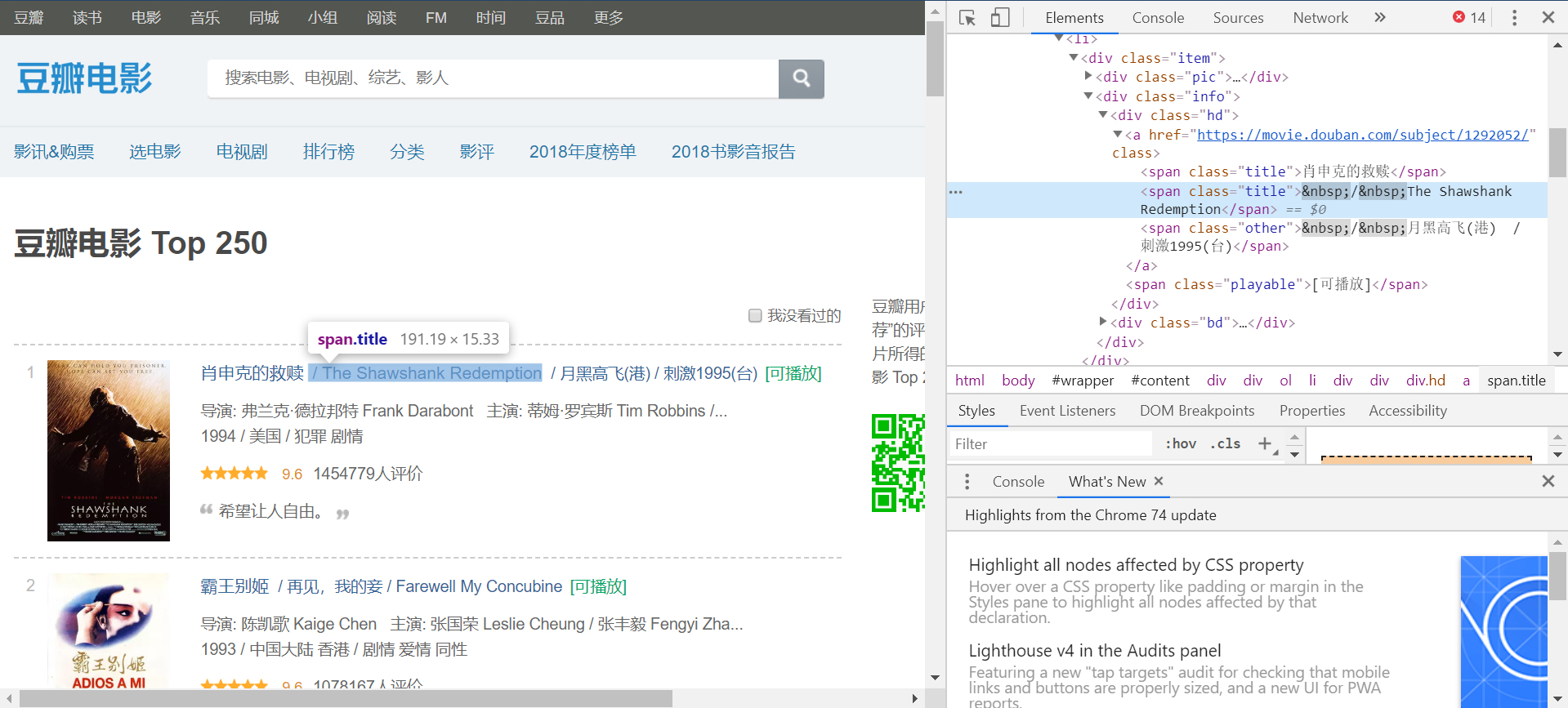
By inspecting the page html code, we see that one page has 25 containers wrapped by the tags <li>...</li>, each corresponding to a movie.
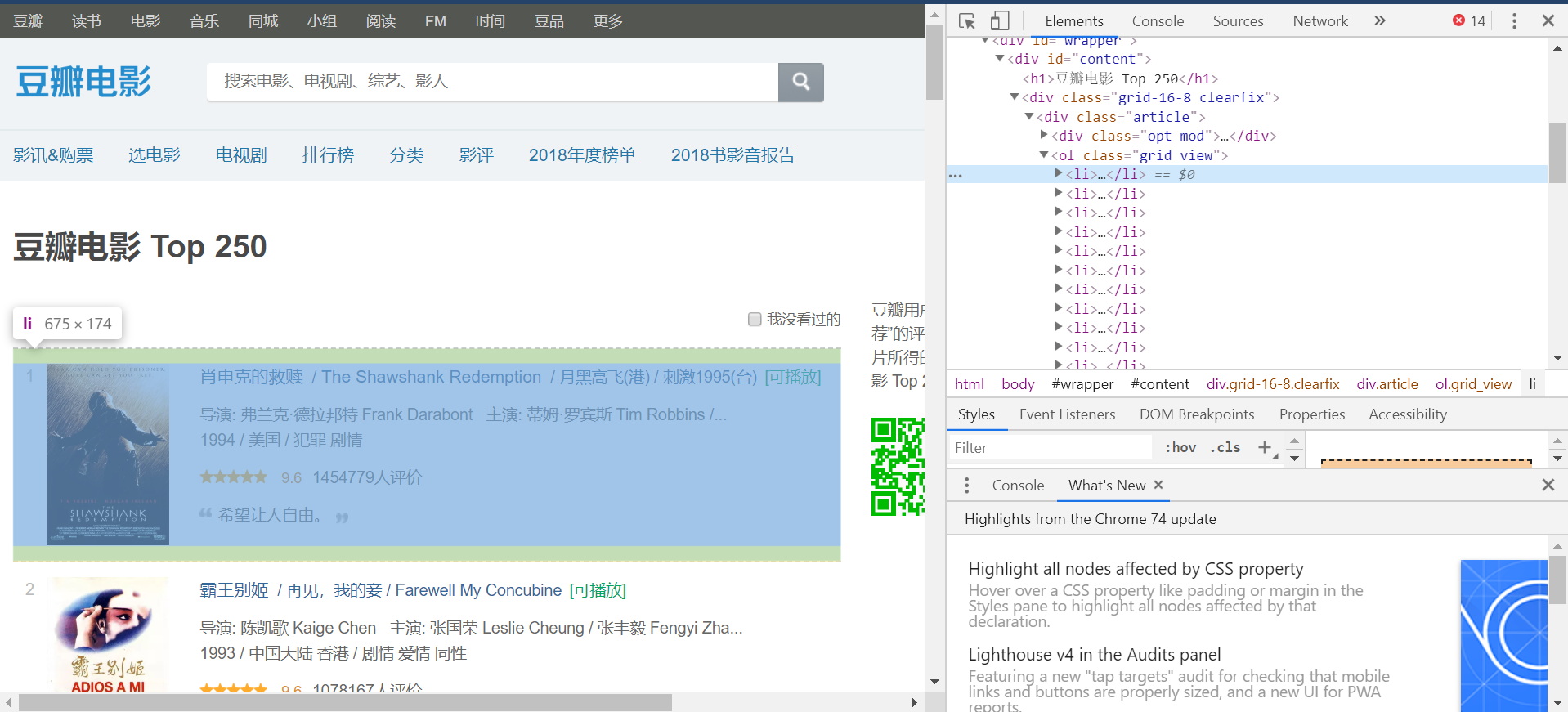
Expanding the code within a container, we can locate the individual code blocks that correspond to the information we want to collect.
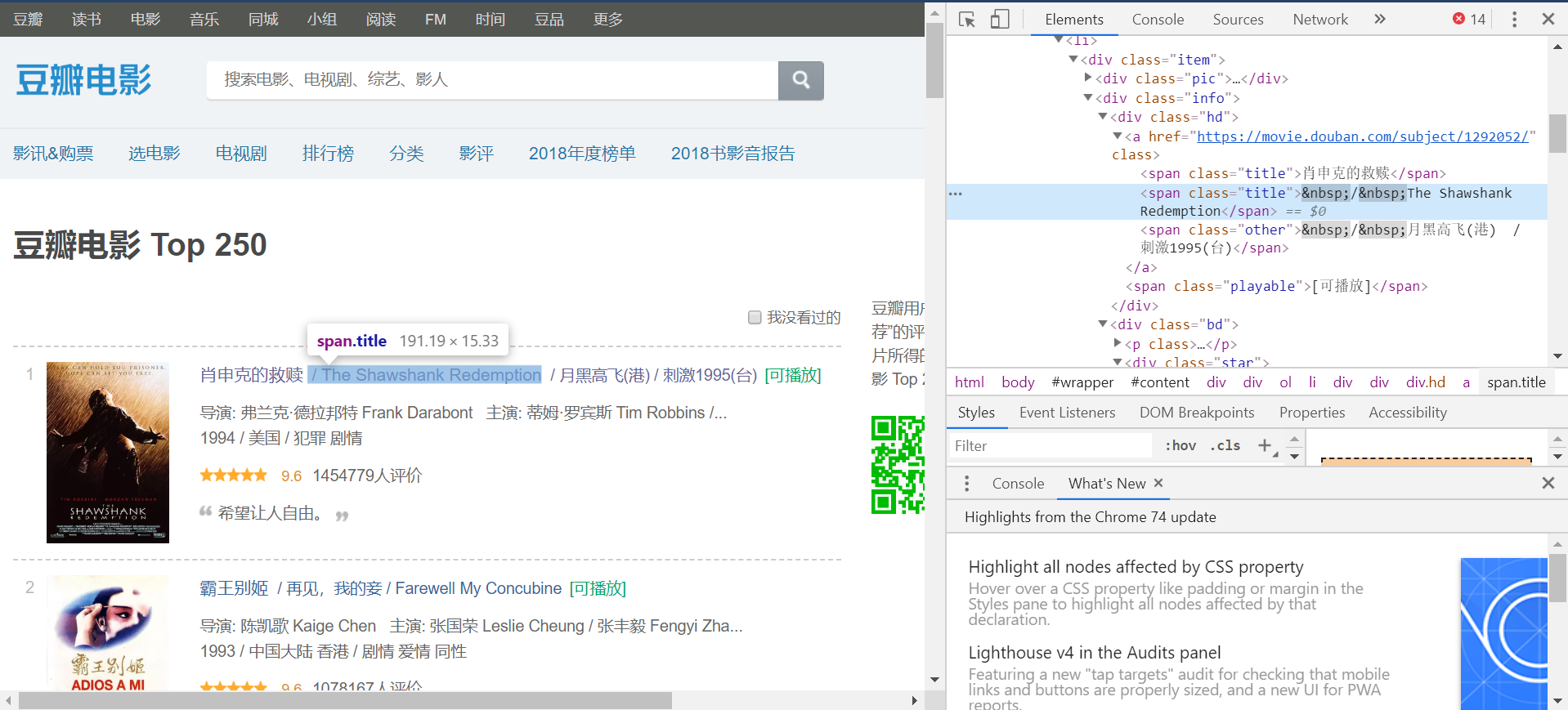
Thus, we can scrape the information as follows. The url of the movie page is contained in the header of the container, wrapped by <div class="hd">...</div>. We can use this observation to locate the url and enter the Douban page of the movie.
# for every one of these 25 containers in a page
for container in movieContainers:
movieInfo = container.find('div', class_="hd")
# enter douban movie page
movieUrl = movieInfo.a.get('href')
doubanMoviePage = requests.get(movieUrl)
# if the movie does not have a douban page, move on to the text one
if "页面不存在" in doubanMoviePage.text:
continue
doubanMoviePageHtml = BeautifulSoup(doubanMoviePage.text, "lxml")
We can now begin to collect the information we need. E.g., to scrape the year the movie is released, we observe that year is wrapped in <span class="year">...</span>.
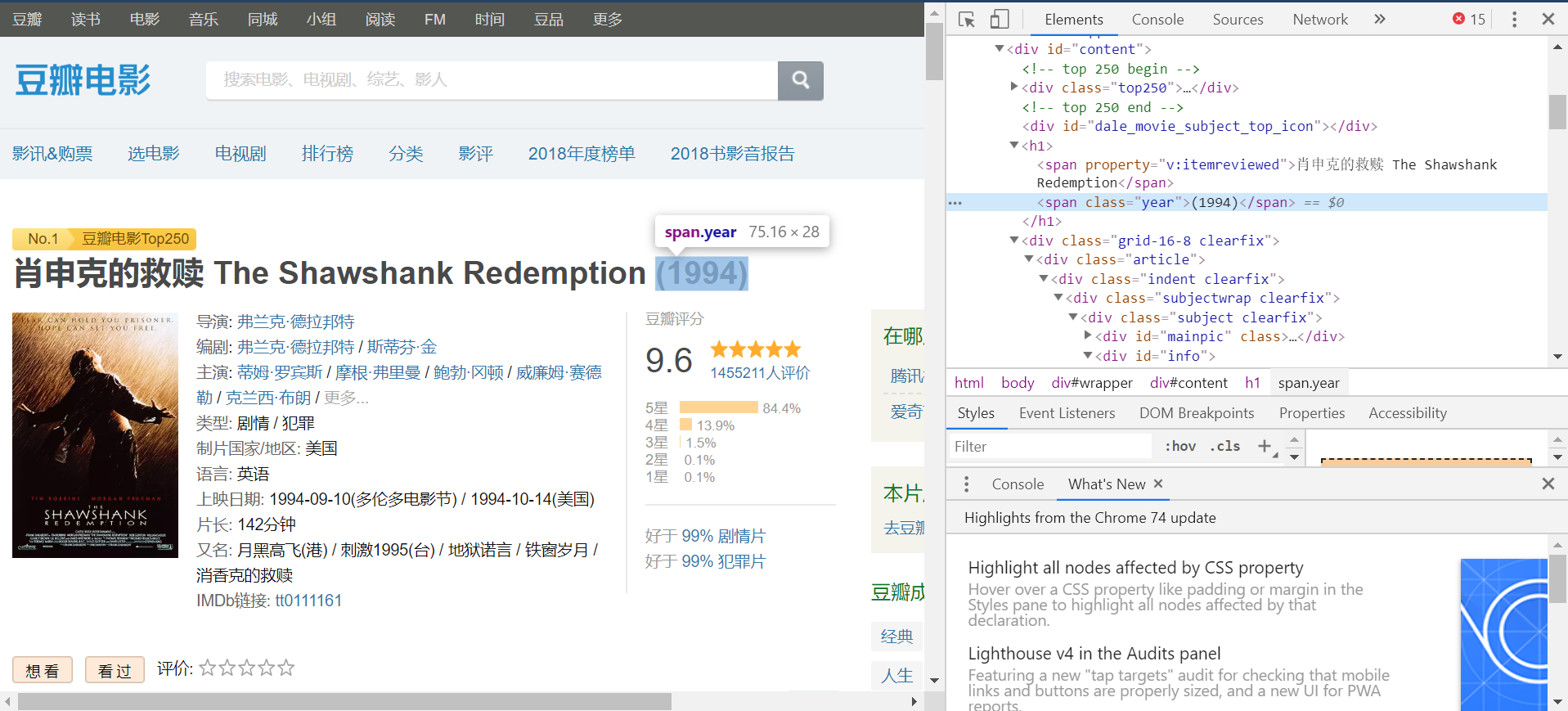
Thus, we can extract year using regular expression as follows.
# scrape year
year = (doubanMoviePageHtml.find("span", class_ = "year")).text
pattern = re.compile(r'(\d{4})', flags=re.DOTALL)
year = (pattern.findall(year))[0]
years.append(year)
Similarly, we observe that the Douban rating is wrapped in
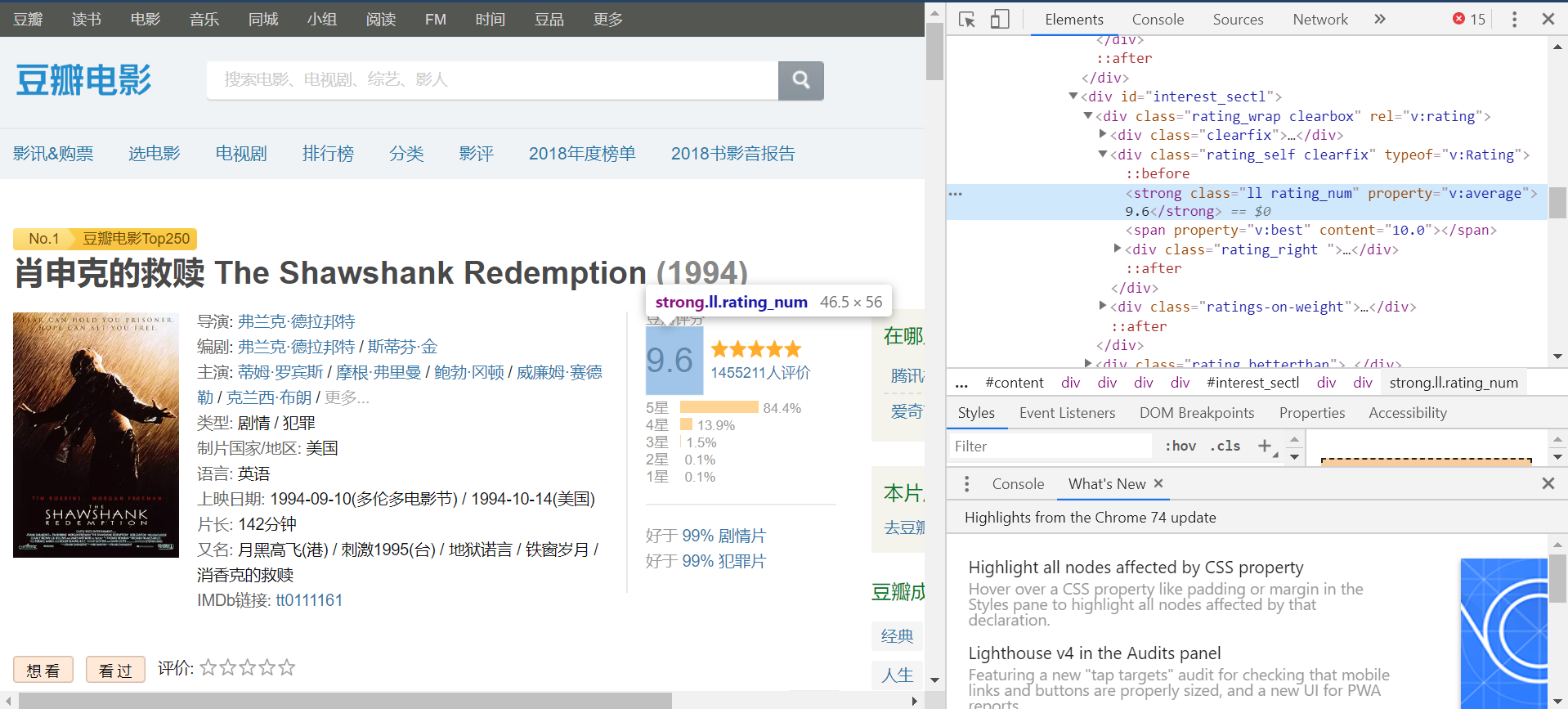
And so it can be extracted like this.
# scrape douban rating
doubanRating = float((doubanMoviePageHtml.find("strong", class_="ll rating_num")).text)
doubanRatings.append(doubanRating)
We still need the movie’s genre, region, and imdb rating. Since genre and region are listed in Chinese on Douban, we will obtain all these remaining information from IMDb.
Luckily, the Douban page contains a link to the movie’s IMDb page. So we can directly access the IMDb movie profile from where we were. Again, a comparison of the html code and the Python code to extract the IMDb link:
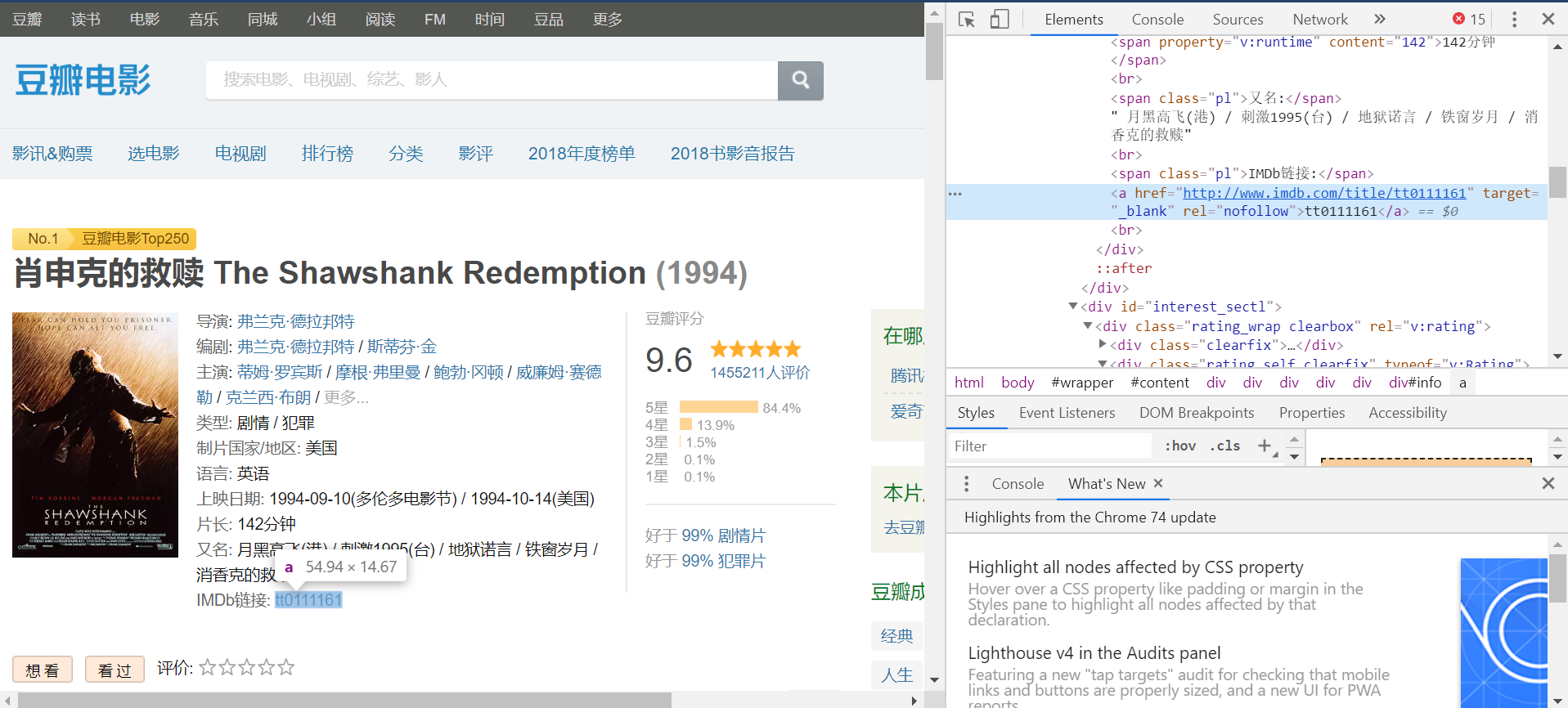
# ender imdb movie page from douban
basicInfo = doubanMoviePageHtml.find("div", attrs={"id":"info"})
pattern = re.compile(r'IMDb链接: tt(\d{7})', flags=re.DOTALL)
imdbId = pattern.findall(basicInfo.text)[0]
imdbUrl = "http://www.imdb.com/title/tt" + imdbId + "/"
print(imdbUrl)
imdbMoviePage = requests.get(imdbUrl)
imdbMoviePageHtml = BeautifulSoup(imdbMoviePage.text, "lxml")
Scraping genre, region, and imdb rating is similar to the above. After we are done, simply combine the lists to a dataframe and write it to a .csv file.
movieInfo = pd.DataFrame({'movie': names,
'year': list(map(int,years)),
'genre': genres,
'imdb': imdbRatings,
'douban': doubanRatings,
'region': regions},
columns = ['movie','year','genre','imdb','douban','region'])
movieInfo.index = movieInfo.index + 1
print(movieInfo.info())
print(movieInfo.head(10))
fileName = "DoubanTop250vsIMDB.csv"
movieInfo.to_csv(fileName, sep = ",", encoding = "utf-8", index = False)
The resulting data file looks something like this:
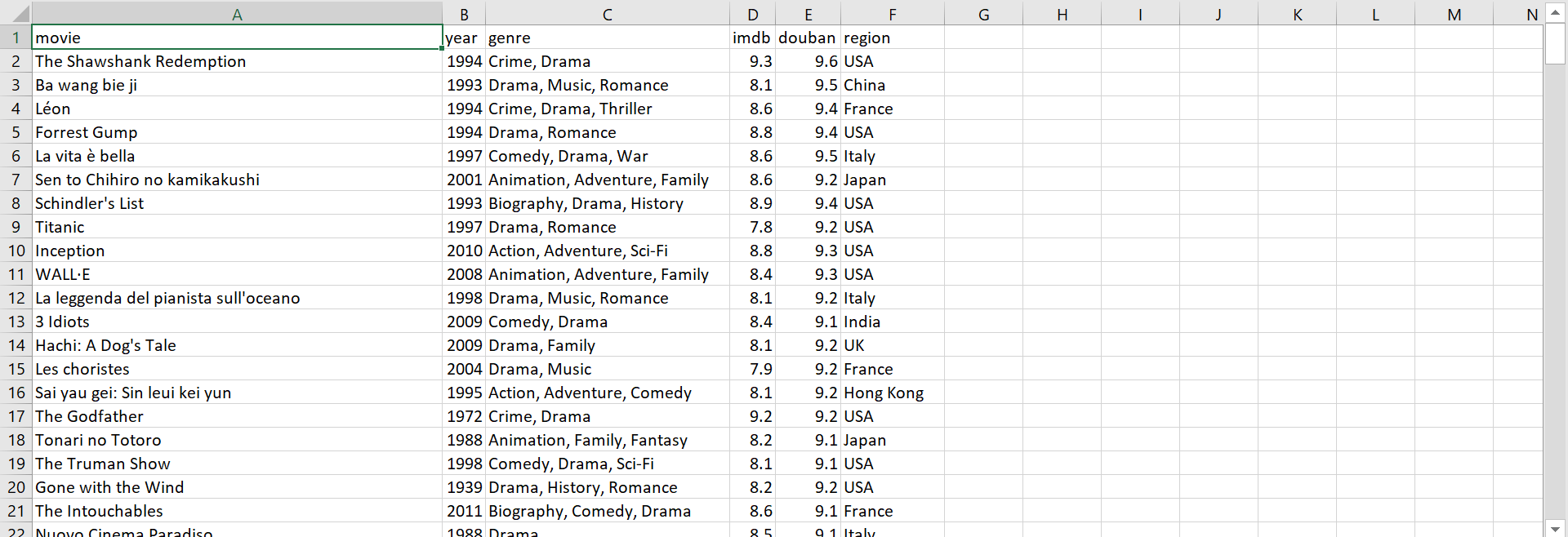
IMDb top 250 vs Douban
Now we turn to the top 250 movies on IMDb. Scraping information from this site is the same game as before. But unlike the previous case, there is no link to a movie’s Douban page on its IMDb page. Thus, we need to search each movie directly on Douban’s site.
Again, we start with importing the modules. These are the same modules as before, with the last two extra lines.
import requests
from lxml import html
import re
import pandas as pd
import numpy as np
import time
import random
from bs4 import BeautifulSoup
from time import sleep
from random import randint
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
Selenium is a tool that automates browsers for automated testing purposes. In web scraping, we may run into cases where the information we need are javascript content which is not in the page’s html, as discussed here. In these cases, instead of directly scraping the page’s html, we need to render the javascript content before scraping. This is where Selenium comes into play. It can mimic user operations on a browser and “fool” the javascript content into loading. A list of webdrivers it supports can be found as follows.
>>> from selenium import webdriver
>>> help(webdriver)
Help on package selenium.webdriver in selenium:
NAME
selenium.webdriver
PACKAGE CONTENTS
android (package)
blackberry (package)
chrome (package)
common (package)
edge (package)
firefox (package)
ie (package)
opera (package)
phantomjs (package)
remote (package)
safari (package)
support (package)
webkitgtk (package)
We will be using chromedriver, which can be downloaded here. We add some further tweaks to disable image-loading in order to save time. We also set a timeout limit of 30s. Then we go to the Douban site.
chromedriver = "path-to\chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
options = webdriver.ChromeOptions()
# do not load images
prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(chromedriver, chrome_options = options)
browser.set_page_load_timeout(30)
browser.get('https://movie.douban.com')
assert "豆瓣电影" in browser.title
The second last line will prompt a browser window to open and visit the given url.
As before, we declare some empty lists to store our data. Then we start parsing the IMDb top 250 page.
# declare lists to store data
names = []
years = []
genres = []
imdbRatings = []
doubanRatings = []
regions = []
# make request
response = requests.get("http://www.imdb.com/chart/top")
# parse page
pageHtml = BeautifulSoup(response.text, 'html.parser')
The top 250 movies are conveniently displayed in one page, so there is no need to turn page as in the case of Douban top 250. For each of these 250 movies, we first scrape its title and year of release from the main page; then we enter the movie’s profile page and extract its IMDb rating, genre, region, etc.
for i in range(0,250):
# pause loop to avoid bombarding the site with requests
sleep(randint(3, 5))
# scrape name
titleInfo = pageHtml.find_all('td', class_ = 'titleColumn')[i]
name = titleInfo.a.text
names.append(name)
# scrape year
year = titleInfo.span.text
pattern = re.compile(r'(\d{4})', flags=re.DOTALL)
year = (pattern.findall(year))[0]
years.append(year)
# enter imdb movie page
imdbMovieUrl = 'http://www.imdb.com' + titleInfo.a.get('href')
imdbMoviePage = requests.get(imdbMovieUrl)
imdbMoviePageHtml = BeautifulSoup(imdbMoviePage.text, 'html.parser')
print(imdbMovieUrl)
# scrape imdb rating
pattern = re.compile(r'<span itemprop="ratingValue">(.+?)</span>', flags=re.DOTALL)
imdbRating = float(pattern.findall(imdbMoviePage.text)[0])
imdbRatings.append(imdbRating)
# ...
Scraping the movies’ Douban ratings is intuitive. Just like using a browser, we locate the search box on the website, type in the keyword, press enter, and then obtain the resulting webpage from the browser. Since the keyword search is not perfectly accurate, the search may return several results, and considering that Douban mainly uses Chinese, the movie we want may not be the first result. Thus, we go through each of the search results and only scrape its rating if the result has matching title and year as the search keyword.
# scrape douban rating
keywords = name + " " + year
# find the searchbox element
elem = browser.find_element_by_name("search_text")
# clear search box
elem.clear()
# enter in search box
elem.send_keys(keywords)
elem.send_keys(Keys.RETURN)
searchPageHtml = BeautifulSoup(browser.page_source, "lxml")
containers = searchPageHtml.find_all('div', class_ = 'item-root')
j = 0
while j < len(containers):
firstContainer = containers[j]
titleInfo = firstContainer.find('div', class_="title").text
# only scrape rating if result has matching title and year
if name in titleInfo and year in titleInfo:
doubanRating = float(firstContainer.find("span", class_ = "rating_nums").text)
break
else:
j += 1
if j == len(containers):
doubanRating = "NA"
doubanRatings.append(doubanRating)
After the loop is finished, as before, we combine the lists to a dataframe and write the results to a .csv file.
movieInfo = pd.DataFrame({'movie': names,
'year': list(map(int,years)),
'genre': genres,
'imdb': imdbRatings,
'douban': doubanRatings,
'region': regions},
columns = ['movie','year','genre','imdb','douban','region'])
movieInfo.index = movieInfo.index + 1
print(movieInfo.info())
print(movieInfo.head(10))
fileName = "IMDBTop250vsDouban.csv"
movieInfo.to_csv(fileName, sep = ",", encoding = "utf-8", index = False)
The resulting data file looks something like this:
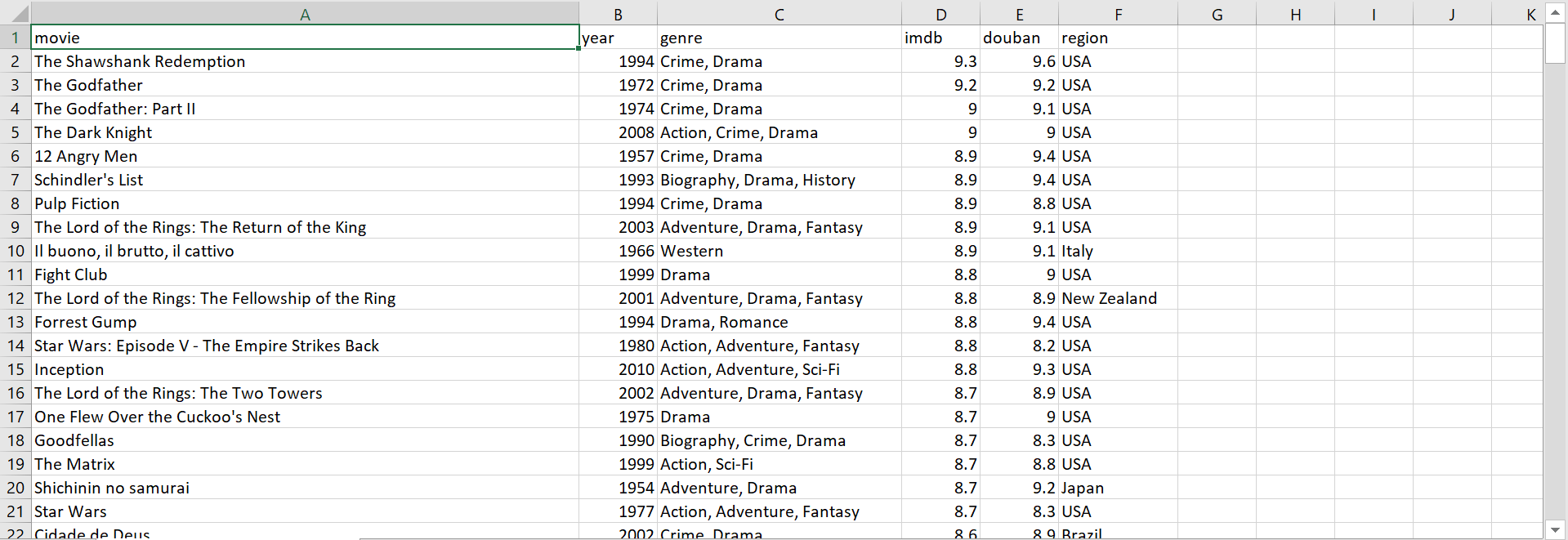
Visualization
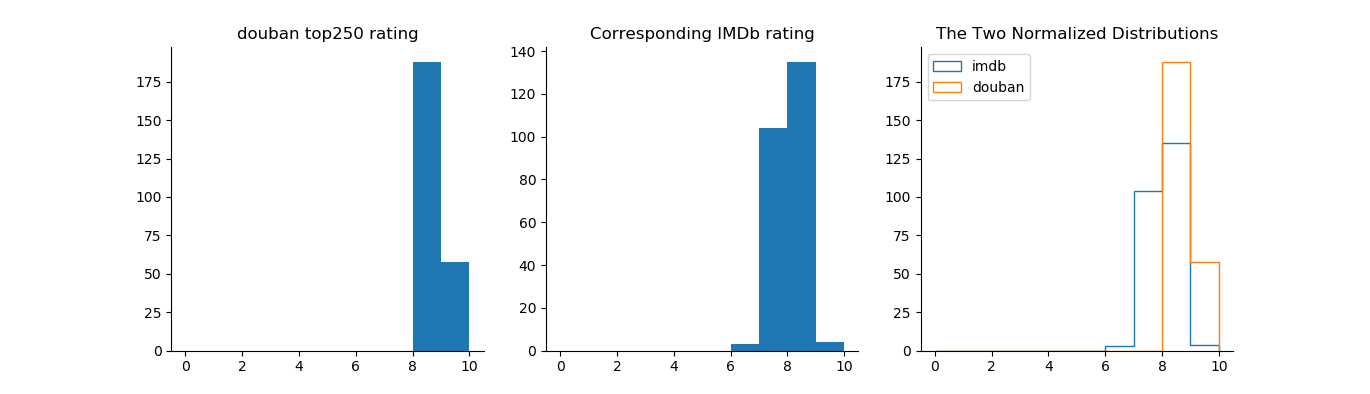
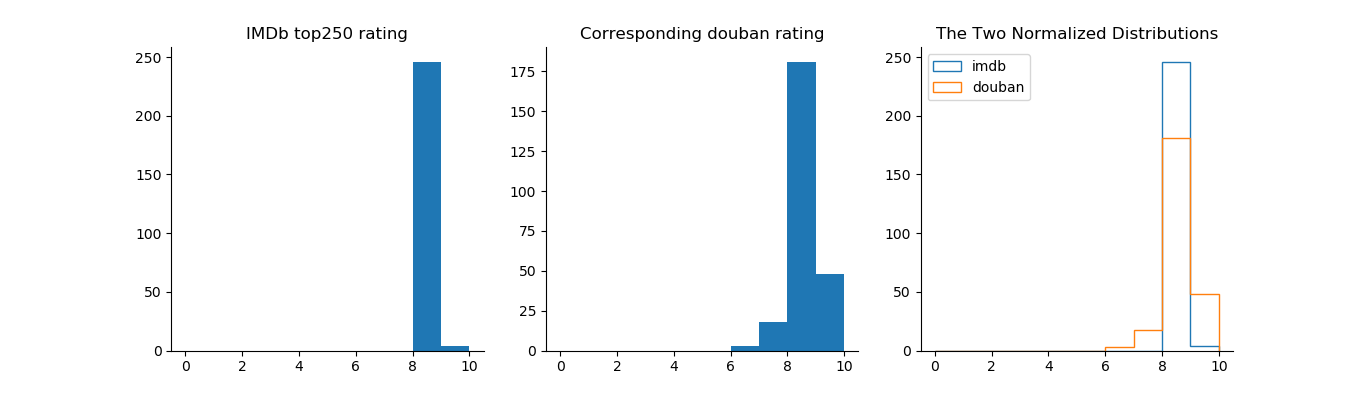
The histograms show that the ratings of both IMDb and Douban’s own top 250 movies are between 8 and 10, with Douban having a slightly higher average. Again for both IMDb and Douban, the ratings of their own top 250 movies have a smaller spread than those on the other site, meaning that both websites have some top movies that are rated either quite a bit higher or lower on the other website. That said, Douban in general seems to be more “tolerant” with the top movies on IMDb than the other way around.
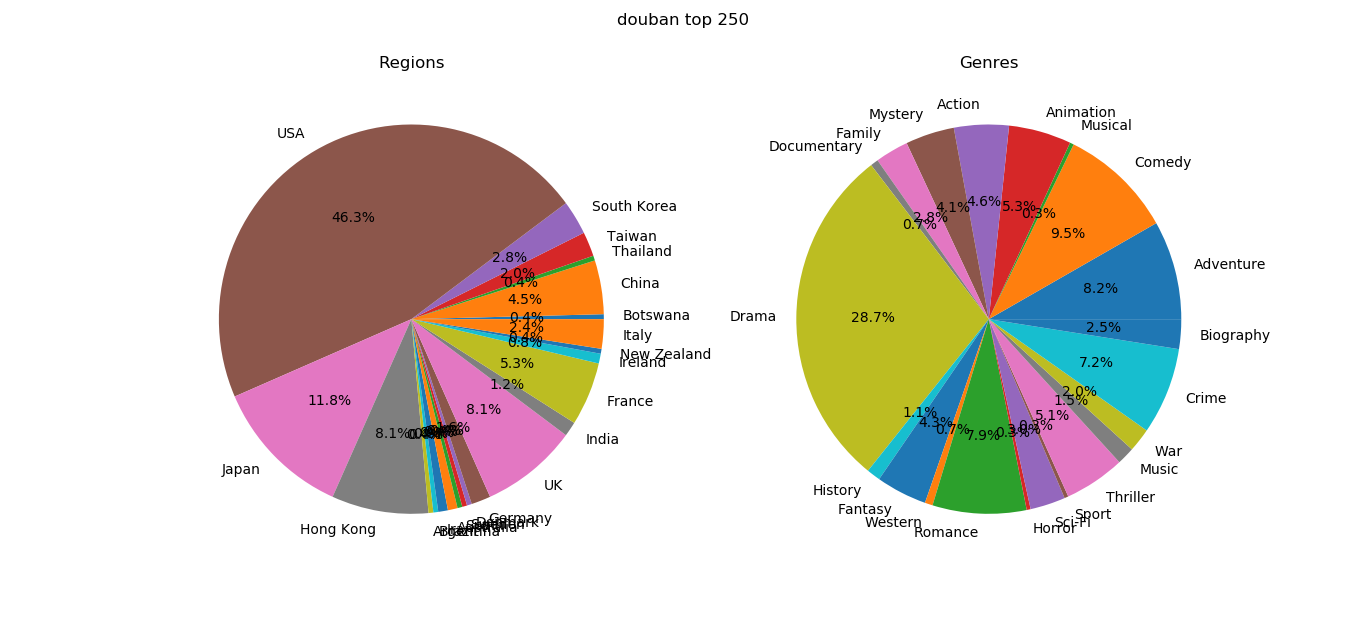
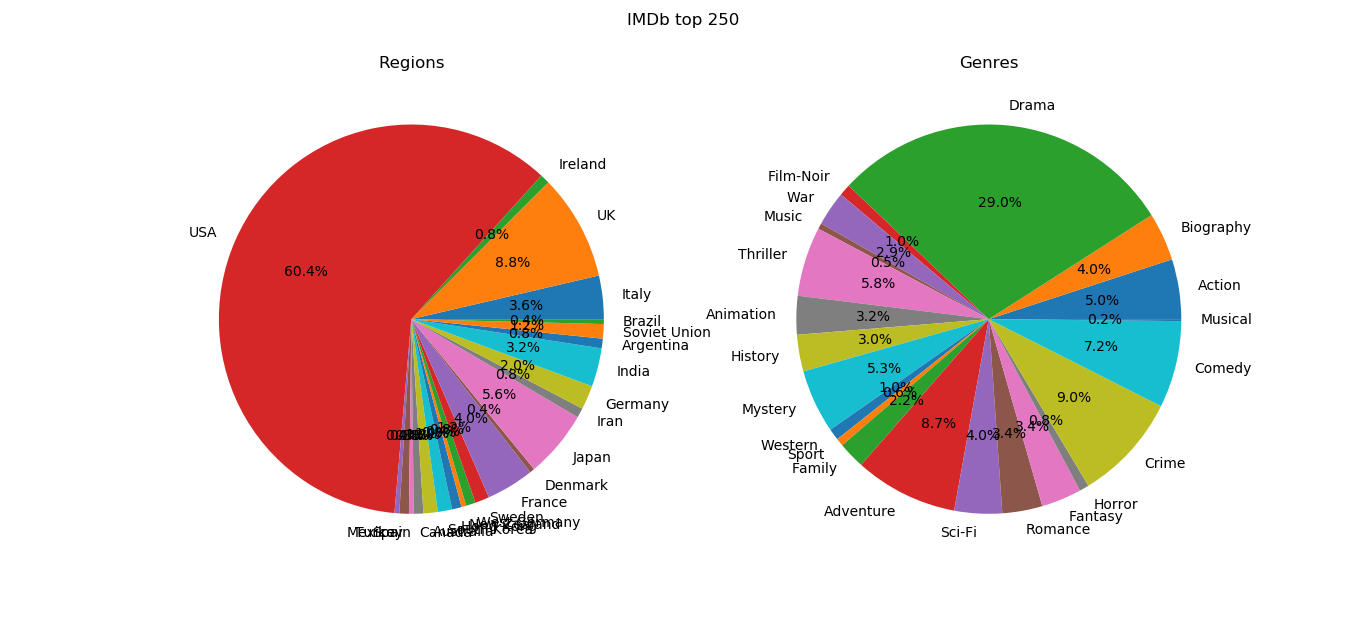
The distributions of genres among the top 250 movies on the two websites seem similar, with the most popular genre being drama, followed by adventure, comedy, crime, etc. Regarding regions, the United States remains the country that produces the most top movies on both websites. Yet there are evidently more movies of Eastern origin among Douban’s top 250 than IMDb’s, e.g., Japan, China, Hong Kong, Taiwan, India, Thailand. Similarly, there are more movies of Western origin among IMDb’s top 250, e.g., the United States alone occupies over half, followed by countries in Europe.